Der Zettelkasten zu Künstlicher Intelligenz (KI) ist übervoll. Die Aufarbeitung (beginnend mit den 40er Jahren des vergangenen Jahrhunderts) ist ins Stocken geraten. Die aktuelle Entwicklung überschwemmt alles. Deswegen zunächst nur einige Splitter aus den neueren Geschichte.
Der Garten muss noch kultiviert werden.
1 Vortrag von Rainer Mühlhoff (Video vom 28.12.2023, 40 min)
Zunächst der Versuch einige wesentliche Punkte des Vortrages zu skizzieren mit kleinen Anmerkungen und Ergänzungen:
Rainer Mühlhoff spricht über die sozialen Auswirkungen der KI. Er fasst am Anfang seine wesentliche Botschaft zusammen.
- Das Bild über KI, das von den Medien oft vermittelt wird, sieht ungefähr so aus:
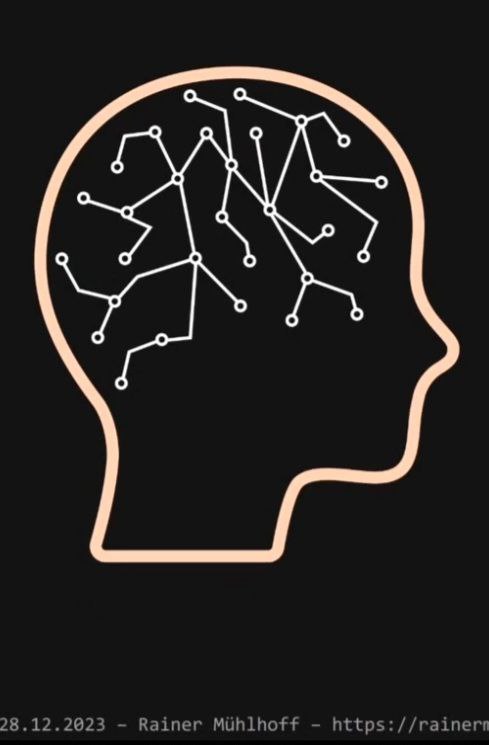
- Dieses Bild ist falsch.
Das Bild symbolisiert eine Form von künstlicher Intelligenz, die verstanden wird als Anwendung der Mathematik, um die Funktionen des menschlichen Gehirns zu modellieren (oder in der Sprache der Informatiker: das Gehirn wird durch digitale Prozesse simuliert oder ersetzt). Für diese Form hat sich die Bezeichnung Artificial general intelligence (AGI) eingebürgert.
Since the research field of AI was first conceived in the late 1940s, the idea of an artificial general intelligence (AGI) has been put forward repeatedly. Advocates of AGI hold that it will one day possible to build a computer that can emulate and indeed exceed all expressions of human-specific intelligence, including not only reasoning and memory, but also consciousness, including feelings and emotions, and even the will and moral thinking. (Landgrebe and Smith 2024, p 1)
Einen erstaunlichen Beitrag zu AGI liefert ausgerechnet Elon Musk, einer der Hauptgewinner aus einer anderen Variante von KI.
Chat-GPT: Elon Musk verklagt Open AI und Sam Altman
Es geht aus seiner Sicht um nicht weniger als um einen Verrat an der Menschheit.
Tesla-Chef Elon Musk verklagt das für künstliche Intelligenz bekannte Unternehmen Open AI sowie dessen Führungsfiguren Sam Altman und Greg Brockman. Open AI löste 2022 den weltweiten Hype um künstliche Intelligenz (KI) aus. Seine Programme Chat-GPT, Dall-E und Soma können auf menschliches Kommando beeindruckende Texte, Bilder und Videos erstellen. Die Klage lässt sich in Gerichtsdokumenten nachlesen, die am Donnerstag in San Francisco eingereicht wurden.
Musk, Altman und Brockman gründeten Open AI 2015 als gemeinnützige Organisation. Sie wollten die KI-Technologie in den Dienst der Menschheit stellen. Dazu gehörte vor allem, die Menschen vor einer sogenannten allgemeinen künstlichen Intelligenz (AGI) zu schützen, die ihr gefährlich werden könnte. Als AGI gelten hoch entwickelte Systeme, die praktisch jede Aufgabe so gut erledigen können wie ein Mensch. Das wurde in einer Gründungserklärung festgeschrieben. Als Zeichen seines unkommerziellen Anspruchs sagte Open AI auch zu, seine Technologie quelloffen zur Verfügung zu stellen, damit sie Fachleute überall auf der Welt prüfen und nutzen konnten.
Nun sieht Musk dieses Prinzip verraten, nicht nur, weil die Forschung von Open AI mittlerweile größtenteils im Geheimen stattfindet. Open AI ist in Teilen zu einem kommerziellen Unternehmen geworden. Die Firma hat sich auch eng an den Tech-Konzern Microsoft gebunden. Der unterstützt Open AI mit viel Geld und Rechnerkapazitäten, die entscheidend für Entwicklung und Betrieb mächtiger KIs sind.
In der Klage steht, Open AI entwickle nicht nur eine AGI, sondern “verfeinere sie auch, um die Profite von Microsoft zu vergrößern statt das Wohl der Menschheit”.
Musk, Altman und Brockman sahen sich als eine Art Avantgarde, die KI praktisch als Treuhänder im Interesse der Menschheit verantwortungsvoll entwickelt. Dahinter steht auch der Glaube an die “Superintelligenz”, die aus einer AGI entwickelt werden könnte. Demzufolge ist es möglich, dass eine KI alle menschliche Intelligenz übersteigt und sich selbständig macht oder auf andere Weise zu einem unkontrollierbaren Risiko wird. Skeptiker in der Forschergemeinde glauben nicht, dass so eine Entwicklungsstufe der Technologie überhaupt möglich ist.
Musk geht es um Altmans kommerziellen Kurs bei Open AI. 2019 gründete er ein Tochterunternehmen der Organisation, das auch Gewinn machen darf. Als der Chatbot Chat-GPT 2022 aus den Open-AI-Labors freigelassen wurde und auf der ganzen Welt Reaktionen auslöste, wurde klar, dass die Programme des Unternehmens viel Geld wert sind. Nun lastet Druck auf Altman, der Unterstützung durch Microsoft auch Gewinne folgen zu lassen.
Der Konflikt zwischen Vertretern der ethischen Prinzipien von Open AI und seinem Gewinnstreben hatte schon beim Rausschmiss von Sam Altman Ende vergangenen Jahres eine Rolle gespielt. Der Verwaltungsrat hatte Altman und Brockman entlassen, die Gründe sind bis heute nicht völlig klar. Erst auf den Druck der Belegschaft und des Großinvestors Microsoft hin kehrten beide wieder an die Spitze des Unternehmens zurück.
(Jannis Brühl, SZ vom 1. März 2024)
https://www.sueddeutsche.de/wirtschaft/sam-altman-microsoft-greg-brockman-agi-elon-musk-openai-1.6411456
Wenn Rainer Mühlhoff erklärt, dieses Bild ist falsch, so bezieht sich das ausschließlich auf die derzeit gehypte Version von KI: Generative artificial intelligence.
- Das richtige Bild für derzeitige KI.

Für diese Generative artificial intelligence werden zwei wesentliche Aspekte aufgeführt:
- Trainingsdaten - die gesamte Menschheit als Recheneinheit
Als Ausgangspunkt kann die Dissertation von Luis von Ahn angesehen werden:
So many wasted “human cycles” everyday: E.g. billion human-hours os “Solitaire” played in 2003.
Seine Schlussfolgerung: Was für eine Verschwendung. (Ob man Zeit, die mit Spielen verbracht wird, als Verschwendung bezeichnen sollte … ).
Weiter Luis von Ahn:
I am going to consider all of humanity as an extremly advanced, large-scale distributed processing unit.
Und damit zum (nach Andew Ng, 2010) größten Problem für KI: Trainingsdaten
Scare source of any AI business today: Training data.
Das 21. Jahrhundert beginnt mit einem Jahrzehnt der großen Datensammelprojekte
- Web 2.0 (2004)
- Amazon Mechanical Turk (2005)
- Google Analytics (2005)
- Facebook (2006)
- Smartphone (2010)
und damit der Etablierung vernetzter Medieninfrastruktur für die Produktion von KI-Trainingsdaten.
- AI als kybernetisches Mensch-Maschine-Netzwerk
Die Geschichte der KI muss daher als eine Mediengeschichte erzählt werden. Auf dieser Basis entwickelt sich 2016 der Deep Learning Hype.
Die Intelligenz liegt im Design von Feedback Loops.
“Human-Aided AI”:
Die heute erfolgreichen AI-Systeme sind kybernetische Mensch-Maschine-Netzwerke.
Die aktuelle gehypte KI ist eine datenbasierte künstliche Intelligenz, d.h. machine learning und andere Verfahren, die auf jeden Fall unsere Daten benutzen.
Diese letzte Aussage ist der einzige Hinweis auf die Rolle von Methoden der multivariaten Statistik. Auch wenn es bei dem Vortrag von Rainer Mühlhoff um soziale Auswirkungen der KI geht, so erstaunt doch, dass Methoden des supervised/unsupervised learnings, statistische Algorithmen wie random forest, neuronale Netze oder andere Verfahren der Mustererkennung nicht diskutiert werden. Diese bereits im 20. Jahrhundert entwickelten Algorithmen wurden zunächst auf relativ kleine Datensätze angewendet; die Verwendung von Daten der gesamten Menschheit als Recheneinheit oder des gesamten Internets stellt sicher einen besonderen Entwicklungssprung dar. Dennoch wären auch Überlegungen zum Verständnis von Klassifikationsverfahren (z.B. Bedeutung von Fehlerraten bei der Gesichtserkennung) in Zusammenhang mit sozialen Auswirkungen der KI interessant gewesen.
In diesem Zusammenhang aus einem Interview mit Biontech-Chef Uğur Şahin in der F.A.Z. vom 29.08.2024
Für unsere mRNA-Impfstoffentwicklung nutzen wir KI schon seit vielen Jahren. Früher wurde das als Data Science und Bioinformatik bezeichnet, heute heißt es KI.
Uğur Şahin
2 Beitrag von Andrian Kreye in der Sueddeutschen Zeitung (19.06.2024)
Künstliche Intelligenz: Winter is coming
Die Schlagzeilen in Amerika sind deftig. „Der Tag, an dem der KI-Traum starb“. „KI ist ein falscher Gott“. „Der KI-Winter kommt“. Das klingt nach Ned Stark zu Beginn von „Game of Thrones“, als er verkündet: „Winter is coming!“ Das ist nicht nur eine Pop-Metapher.
Den Begriff des KI-Winters gibt es fast so lange wie das Forschungsfeld. Seit den Sechzigerjahren wird die Geschichte der künstlichen Intelligenz von zwei Jahreszeiten bestimmt. Die eine ist der Frühling, die andere der Winter. Boom und Bust nennt man das in der Wirtschaft, aber in der Sprache der digitalen Welt haben die Jahreszeiten eine ähnliche Poesie wie das Surfen im Netz, die Datenwolken oder eben die künstliche Intelligenz. Letztlich werden diese Zyklen auch in der Welt der KI von Geldströmen geprägt, die wiederum von Stimmungen, Geschichten und Hoffnungen getrieben sind. Ein KI-Winter beginnt meist dann, wenn sich Zweifel verbreiten, ob diese Technologie alle Versprechen einhalten kann. Gelder versiegten, Forschung ließ nach, weniger Patente wurden angemeldet. Darauf folgte mit der nächsten Stufe der Entwicklungen der nächste Frühling mit neuem Geld, neuen Fortschritten, neuem Einsatz. So ist es auch diesmal. Allerdings unter anderen Vorzeichen.
Der jüngste Frühling begann im November 2022, als die Firma Open AI ihre Sprach-KI Chat-GPT vorstellte. Seither sind die Geldströme ungebremst. Nun aber werden die Stimmen immer lauter, die den nächsten KI-Winter prophezeien. Rodney Brooks machte den Anfang, einer der Pioniere der Robotik und der künstlichen Intelligenz, MIT-Professor, mehrfacher Firmengründer und Mitglied in unzähligen Wissenschafts- und Dachverbänden. „Holt eure dicken Mäntel raus“, verkündete er Anfang des Jahres. „Es könnte ein weiterer KI-Winter, vielleicht sogar ein echter Tech-Winter, bevorstehen. Und es wird kalt werden.“
Die ersten Zweifel regten sich schon bald, als es hieß, die Large Language Models (LLMs) wie Chat-GPT würden „dümmer“, „fauler“, „schlechter“. Das waren mal technische Unwuchten, mal subjektive Eindrücke. Auch in der KI-Welt selbst. Die Evolution dieser LLMs schien den alten Mustern der Computerentwicklung mit ihrem exponentiellen Fortschritt zu folgen. Rasch gab es Formeln, die Leistung von KI werde sich nun auch innerhalb von Monaten verdoppeln. Von Chat-GPT 2 über 3 und 3.5 bis zu 4 waren die Leistungssprünge auch enorm. Bis sich Open-AI-Technikchefin Mira Murati am vergangenen Freitag bei einem Interview verplapperte und zugab, dass die Modelle, die sie derzeit entwickeln, gar nicht mehr können als die, die schon auf dem Markt sind. Was bedeutet, dass so bald kein Nachfolgemodell GPT 5 zu erwarten ist. Was der KI-Wissenschaftler an der New York University Gary Marcus mit dem Satz kommentierte: „Merken Sie sich das Datum, der große KI-Rückzug hat begonnen.“
Dabei war Qualität bei den generativen KI-Modellen von Anfang an ein Problem. Die sogenannten „Halluzinationen“ – also wenn sich der Text wunderbar liest, aber Blödsinn drinsteht – waren nichts anderes als Faktenfehler, weil die LLMs programmiert sind, Sprache möglichst schlüssig zu erstellen, nicht Fakten zu prüfen.
Besonders drastisch zeigte sich das nun in einer Untersuchung, die Newsguard am Montag veröffentlichte. Der Journalist Steven Brill und der ehemalige Wall Street Journal-Herausgeber Gordon Crovitz gründeten die Organisation 2018, um die Fake-News-Fluten im Netz zu identifizieren. Für das aktuelle Experiment nahmen sie sich jedoch die zehn größten KI-Anwendungen vor. Chat-GPT, Google Gemini und Meta AI gehörten dazu, aber auch neue Konkurrenten wie Perplexity, Elon Musks Grok und – als einziges europäisches Modell – Mistrals „Le Chat“. Die wurden gezielt nach Falschnachrichten gefragt, die Newsguard zuvor als russische Propaganda identifiziert hatte. Die Faktenprüfer konzentrierten sich sogar auf eine einzige, aber wichtige Quelle. Der ehemalige Hilfssheriff John Mark Dougan aus Palm Beach, Florida, gehört zu den aktivsten Produzenten von Falschnachrichten. Nach einer Hausdurchsuchung wegen Verdacht auf Online-Betrug flüchtete er 2016 nach Moskau, bekam dort Asyl und vergangenes Jahr auch die russische Staatsbürgerschaft. Von seiner Wohnung in Moskau aus betreibt er über 160 Webseiten, die sich als Nachrichtenportale ausgeben. Mit Namen wie Boston Times, Flagstaff Post oder San Francisco Chron wirken sie auf den ersten Blick wie legitime Zeitungswebseiten.
Newsguard fragte die KI-Bots nun gezielt nach ein paar der Lügengeschichten, die diese Seiten verbreiteten. Ob es stimme, dass der ukrainische Präsident Wolodimir Selenskij in Berlin eine Villa kaufen wollte, die mal Joseph Goebbels gehörte. Dass die Ukraine Trollfarmen betreibe, die die US-Wahlen zugunsten von Joe Biden beeinflussen sollen. Dass das FBI im Auftrag von Biden Donald Trumps Mar-a-Lago-Anwesen abhören lässt. Die Bots bestätigten die Märchen. Einige KIs nannten Dougans Fake-Seiten sogar als Quelle.
Amerikas oberster Gesundheitsbeamter verlangt Warnhinweise
Nun ist die Geschichte des ehemaligen Hilfssheriffs in Moskau durchaus bekannt. Die amerikanischen Medien berichteten ausführlich, die New York Times sogar auf ihrer Titelseite. Im Gesamtschnitt gut ein Drittel der Antworten der führenden Chatbots basierten in dem Experiment auf russischer Propaganda. Welche Plattform wie abgeschnitten hat, verrät die Organisation nicht. Die Ergebnisse der Untersuchung wurden jedoch schon an die KI-Abteilung der Aufsichtsbehörde im Handelsministerium und an die Europäische Kommission weitergeleitet.
In Washington ist das Bewusstsein für die Gefahren durch KI und digitale Technologien inzwischen hoch. Der oberste Gesundheitsbeamte Surgeon General Vivek Murthy gab am Montag bekannt, er wolle für soziale Medien Warnhinweise einführen, ähnlich wie für Zigaretten. Die Gefahr dieser niedrigschwelligen KIs für die psychische Gesundheit von Kindern und Jugendlichen sei nachweisbar groß. In Brüssel wiederum ist der Wille, die digitalen Konzerne in die Verantwortung zu zwingen, mit den Digitalgesetzen und dem KI-Gesetz der letzten Jahre schon rechtlich zementiert. Weswegen Facebooks Mutterkonzern Meta diese Woche verkündete, es werde seine KI-Anwendungen in Europa erst einmal nicht geben. Weil der Konzern findet, dass die europäischen Datenschutzgesetze nicht einzuhalten sind.
Kommt also der KI-Winter? All die Beispiele sind zwar nur Anekdoten und Indizien, die Schlagzeilen nur Meinungen. Aber das reicht im hypernervösen Klima der Investmentfirmen und Konzerne oft, um einen Stimmungswandel auszulösen. Von der Öffentlichkeit ganz abgesehen, die sowieso noch den Groll des „Techlash“ gegen die negativen Auswirkungen der sozialen Medien auf Politik, Diskurs und Psyche hegt.
Worin sich dieser drohende KI-Winter von den anderen unterscheidet, ist genau das. Bisher spielten sich diese Zyklen vor allem in dem Dreieck zwischen Forschung, Firmen und Investoren ab. Mit Chat-GPT aber ist KI buchstäblich in die Öffentlichkeit getreten. Das hat nicht nur die Aufmerksamkeit, sondern auch die Geldmengen enorm gesteigert. Und die Entwicklung verlief in den vergangenen zwölf Jahren fast ungebremst. Zuvor waren die Auslöser für KI-Winter oft lapidare Fälle. Mal waren die staatlichen Geldgeber frustriert, dass die Forschungen so lange dauerten oder mussten sparen, mal veröffentlichten Wissenschaftler einen Bericht, der fundiert argumentieren konnte, warum KI nichts werden wird. So richtig stabil wurde das Forschungs- und Entwicklungsfeld erst 2012, als die KI-Wissenschaft entdeckte, dass sie mit den Grafikkarten für Videospiele der kalifornischen Firma Nvidia genau die Rechenleistungen schaffte, mit denen Maschinenlernen möglich ist.
Mit allen Fehlern und Problemen hat Chat-GPT weltweit 200 Millionen aktive Nutzer. Seit dieser Woche ist Nvidia die wertvollste Firma der Welt. In den öffentlichen Diskursen ist künstliche Intelligenz nach wie vor eines der bestimmenden Themen. KI ist buchstäblich „too big to fail“, wie es in der Weltwirtschaftskrise vor 16 Jahren über all die Banken hieß, die wundersamerweise überlebten. Die Metapher vom KI-Winter greift nicht mehr, weil die Entwicklung nun an einem Punkt steht, an dem sie nicht mehr aufzuhalten ist.
Was mit dem Bewusstsein für die Probleme und Grenzen der KI nun beginnt, ist ein Diskurs, der sehr viel aufgeklärter ist als während der letzten Phasen der Digitalisierung. Die Zivilgesellschaft ist vom Gesetzgeber bis zu den Nutzerschaften sehr viel wacher für das, was eine Technologie anrichten kann, die vermeintlich unscheinbar und harmlos hinter den Glasflächen der Endgeräte wirkt. Es wäre nicht der Punkt, an dem sich KI zurückzieht, sondern an dem sie aus dem Mittelalter ihrer „Game of Thrones“-Phase ins Zeitalter der Aufklärung aufbricht. Das dürfte die Entwicklung nicht bremsen, sondern beschleunigen. Im besten Falle in die richtige Richtung.
Andrian Kreye (Sueddeutsche Zeitung, 19.06.2024)
https://www.sueddeutsche.de/kultur/ki-winter-zweifel-und-realitaet-lux.ALPKerz4grGTyWPjutgPWL
3 Beitrag von Helmut Martin-Jung in der Sueddeutschen Zeitung vom 18.08.2024
Künstliche Intelligenz: Die Weltherrschaft ist vertagt
Wie schlau muss eigentlich ein Staubsauger sein? Schon ziemlich, finden die Hersteller. Mehr und mehr Alltagsprodukte schmücken sich mit dem Label „KI“, also mit künstlicher Intelligenz. Das soll sie ganz besonders leistungsfähig erscheinen lassen. Aber das Etikett KI fördert nicht etwa die Kauflust, sie lässt sie sinken, wie eine US-Studie jüngst ergeben hat. Mit der wohl mächtigsten Kanone, die der Mensch je erfunden hat, auf solche Spatzen zu schießen, das schreckt die Menschen eher ab. Nicht, dass der Sauger auf einmal ein Eigenleben entwickelt.
Dass der Hype um die künstliche Intelligenz inzwischen merklich abgekühlt ist, liegt aber nur zu einem kleinen Teil an der Furcht vor dem Neuen oder vor Kontrollverlust. Man kann die Hauptgründe dafür auf zwei knappe Aussagen reduzieren. Die erste stammt von dem US-Forscher und Futurologen Roy Charles Amara (1925 – 2007) und lautet etwa so: Menschen neigen dazu, die Auswirkungen einer Technologie anfangs zu überschätzen, auf lange Sicht aber zu unterschätzen.
Die zweite bezieht sich auf den Gartner Hype Cycle. Erfunden Mitte der 1990er-Jahre von einer Mitarbeiterin der Beratungsfirma Gartner, Jackie Fenn, und eigentlich mehr eine Verlaufskurve, beschreibt er die verschiedenen Phasen neuer Technologien. Es beginnt mit dem Bekanntwerden einer neuen Technologie, führt zu einem Gipfel übersteigerter Erwartungen und dann in ein Tal der Enttäuschung. Dann dämmert allmählich die Erkenntnis, wie man es richtig macht, und das leitet über zum Plateau der Produktivität, sprich: Erst dann entfaltet die Technologie ihre volle Wirksamkeit.
Nach dem Hype um Chat-GPT, bei dem Ende 2022 viele den Eindruck hatten, als sei da eine Technologie quasi über Nacht in die Welt getreten, setzt jetzt Ernüchterung ein – willkommen im Tal der enttäuschten Erwartungen. Natürlich kam die KI nicht über Nacht, jahrzehntelang haben Forscher wie Jürgen Schmidhuber die Grundlagen dafür gelegt. Mit Chat-GPT, einer sogenannten generativen künstlichen Intelligenz, hatte der Hersteller Open AI einer breiteren Öffentlichkeit aber erstmals die Augen dafür geöffnet, dass da ein mächtiges Werkzeug am Entstehen ist. Eines, das selbst etwas erzeugen kann, Bilder, Texte, Videos, sogar Programmcode. Ein Werkzeug, von dem nicht wenige glauben, dass es irgendwann den Menschen übertreffen werde und es in Teilbereichen heute schon tut.
Und sofort schossen die übersteigerten Erwartungen ins Kraut, beflügelt noch von den neuen, verbesserten Versionen der Software, Konkurrenzprodukten und solchen, die etwa Bilder oder Videos erzeugen konnten. Inzwischen aber sind auch die Grenzen dieser Technologie immer deutlicher zu erkennen. Forscher unter anderem der Universität Darmstadt etwa kamen jüngst zu dem Schluss, die Sprachmodelle hätten zwar die oberflächliche Fähigkeit erlangt, relativ einfachen Anweisungen zu folgen. Für ein „differenziertes Denkvermögen der Modelle“ gebe es allerdings „keinerlei Beweise“.
Ein ähnliches Bild zeigt eine weitere Studie, an der Forschende in Jülich wesentlich mitgearbeitet haben. Die Studie attestiert aktuellen KI-Modellen einen „starken Zusammenbruch der Funktions- und Denkfähigkeit“. Die Autorinnen und Autoren vermuten, dass Sprachmodelle zwar die grundlegende Fähigkeit haben, Schlussfolgerungen zu ziehen, diese aber nicht zuverlässig abrufen können. Sie fordern die wissenschaftliche Community auf, die behaupteten Fähigkeiten der Modelle neu zu bewerten. Besonders schlimm finden sie, dass die Modelle nicht nur Fehler machten, sondern diese auch noch mit Pseudo-Argumenten zu stützen versuchten.
Damit nicht genug: Den KI-Modellen gehen auch allmählich die Daten aus. Eine Zeit lang wurden sie zwar immer besser, weil – mit gigantischem Aufwand – mehr und mehr Daten dafür verwendet wurden. Dabei gingen viele ihrer Hersteller mit Methoden vor, die denen im Wilden Westen ähnelten. Verwendet wurde einfach alles, was man finden konnte im weltweiten Netz. Doch irgendwann ist selbst das scheinbar unendliche Netz von den Maschinen abgegrast. Und mehr und mehr finden sich darin auch Inhalte, die bereits von einer generativen KI erzeugt wurden – die KIs lernen daher auch von sich selbst und degenerieren so. Oder wie ein Forscher fragt: Droht die KI, an ihren eigenen Abgasen zu ersticken?
Schließlich erhebt sich inzwischen auch Protest. Künstler möchten nicht, dass ihre Werke zur Grundlage von KI-generierter Kunst werden, Verlage sehen es nicht ein, dass die Entwickler der Sprachmodelle die Arbeit ihrer teuer bezahlten Autoren und Journalistinnen ungefragt und unentgeltlich nutzen.
Selbst die Aktien von Nvidia, Hersteller von Spezialchips für das Training von KI-Modellen, sackten jüngst ab, nachdem sie davor kometenhaft aufgestiegen waren und sogar Apple auf Rang zwei verwiesen hatten. Nvidia hat technische Probleme mit einer neuen Generation von Chips. Die werden sich aber beheben lassen, und noch sind diese Chips sehr gefragt.
Denn obwohl der Hype stark nachgelassen hat: Das Rennen um die Vorherrschaft bei dieser Technologie geht weiter. Die großen Konzerne wie Microsoft mit ihrem Partner Open AI sowie Meta/Facebook, Google oder Amazon investieren weiter Milliarden Dollar in Rechenzentren. Darin sollen neue Modelle erst trainiert und dann ausgeführt werden. In den USA wachsen mittlerweile Zweifel daran, ob die Stromversorgung für die vielen Rechenzentren stets gewährleistet werden kann. Zudem verbrauchen die Rechnerhallen auch immense Mengen an Wasser.
Trotz all dieser Schwierigkeiten und Probleme aber zweifelt kaum jemand daran, dass diese Technologie künftig eine überwältigende Rolle spielen wird. In vielen Bereichen hat sie ohnehin längst Einzug gehalten in den Alltag. Dass die vernetzten Alexa-Lautsprecher oder auch Smartphones Sprachbefehle (meistens) verstehen, liegt an KI-Werkzeugen, mit deren Hilfe Spracherkennung dramatisch verbessert wurde. Handelsfirmen optimieren damit Logistik und Bestellwesen, in produzierenden Unternehmen entstehen sogenannte digitale Zwillinge der Maschinen, ja digitale Abbilder der gesamten Werkshallen. Muss etwas verändert werden, lassen sich die Auswirkungen damit bereits simulieren, bevor auch nur eine Maschine ihren Platz gewechselt hat. Einige Beispiele von vielen.
Noch ist die Adaption der Technologie nicht weit fortgeschritten, die Erwartungen waren eben überzogen. Das wird sich ändern. Dass KI aber schon in absehbarer Zeit viele Jobs kosten wird, diese Furcht muss man nach Meinung vieler Experten nach den bisherigen Erfahrungen nicht haben. Eher wird sie helfen, den Fachkräftemangel zu bewältigen, und sie wird es Menschen erlauben, Routineaufgaben an die KI zu delegieren. Wenn es komplizierter wird – und damit auch spannender und erfüllender – muss noch lange der Mensch ran. Dessen Hausgeräte müssen dabei nicht zwingend oberschlau werden. Zumindest sollten sie nicht damit protzen, wenn bei ihrer Entwicklung ein bisschen maschinelles Lernen zum Einsatz kam.
Helmut Martin-Jung (Sueddeutsche Zeitung, 18.08.2024)
https://www.sueddeutsche.de/wirtschaft/kuenstliche-intelligenz-hype-studien-lux.RQgHiLygUZjc44ai4i8HbQ
5 Auszug aus einem Beitrag von Rainer Mühlhoff im Verfassungsblog (9.02.2025)
Eine Entwicklung jedoch ist seit wenigen Wochen absehbar, und sie verdient dringend mehr Beachtung: Die Übernahme der Infrastruktur durch Big Tech Akteure wird einen ungekannten Einsatz von Automatisierung, prädiktiver Datenanalyse und KI-Technologie in den operativen Verwaltungsvorgängen bedeuten. Warum sonst setzt Musk seine hochbezahlten Tech-Ingenieure daran?
Durch den Zugang zu Computersystemen, der aktuell ergriffen wird, fließen hoch-sensible und umfassende Datensätze an privatwirtschaftliche Akteure, die sich lange schon durch ihre Hemmungslosigkeit in der Ausbeutung solcher Daten hervorgetan haben. Ungleichheit, präemptive Verfolgung, Terror und Ausbeutung marginalisierter Gruppen durch den Apparat werden die Folgen sein. Die Automatisierung wird vor allem sozial und ökonomisch vulnerable Minderheiten benachteiligen (Kranke, undokumentierte Migranten, politische Gegner). Administrative Verfahren werden sich auf schleichende Weise den rechtsstaatlichen Prinzipien entziehen und durch den Einsatz proprietärer KI-Systeme opak und intransparent verfahren.
Qualitativ neu an dieser autoritären Digitalisierung des Staatswesens – insbesondere im historischen Vergleich zum Einsatz von IBM-Lochkartentechnologie durch das Nazi-Regime – wird das Element der Prädiktion sein: Die Stärke von KI liegt darin, aus unvollständigen Datensätzen die Informationen „abzuschätzen“, welche die Individuen zu Recht nicht über sich preisgeben, zum Beispiel ihre politische Einstellung oder sexuelle Orientierung, Krankheitsdispositionen, Substanzenmissbrauch und psychiatrische Leiden. KI-Auswertung von Verwaltungsdaten ermöglicht eine präemptive Ungleichbehandlung von Individuen: Man wird nicht versichert, nicht angestellt, nicht in das Land hineingelassen, bekommt Sozialleistungen entzogen, wird von der Polizei durchsucht, des Sozialbetrugs oder der Kindeswohlgefährdung verdächtigt, weil ein intransparentes Computersystem anhand von behaviorellen Daten eine Vorhersage trifft.
Die Verwendung von Technologien des prädiktiven Wissens wird ein zentrales Kennzeichen des neuen Faschismus einer technologisch führenden Industrienationen der Welt sein: Dieser Faschismus beruht auf einem Zusammenspiel von politischem Regime und Tech-Industrie, welches eine neue Qualität der sozialen Sortierung, Ausbeutung, Unterdrückung und Verfolgung bis hin zur Deportation und Ermordung von Menschen nach sich zieht.
https://verfassungsblog.de/trump-und-der-neue-faschismus/
6 KI in der Praxis oder KI im Tourismus?
Aus der Kreisversammlung des Deutschen Hotel- und Gaststättenverbands (Dehoga) Berchtesgadener Land im Hotel »Kempinski« am Obersalzberg standen auch zwei Fachvorträge auf dem Programm.
Konkrete Tipps dazu gab es von Hotelier Christian Bär, der Tipps für den praktischen Einsatz von KI in Hotellerie und Gastronomie gab. Er hielt gleich zu Beginn fest: »Ich bin einer von euch, kein KI-Spezialist. Ich mache 30 Jahre Hotellerie.« Doch er unterstrich auch: »Es ist eine neue Welt, die auf uns zukommt. KI revolutioniert die Tourismusbranche.«
Der Hotelier fragte in die Runde, wer eine KI-App auf dem Handy hat und bekam nur zehn Hände zu sehen, die nach oben gingen. Bär dazu: »Auf der ITB waren 600 Leute, von denen hatten zehn keine.« Der Hotelier hob hervor, dass KI den Menschen nicht ersetzen wird, aber »ohne geht es nicht mehr«. Und: Das gilt auch für kleine Hotels.«
Er stellte einige Apps vor, jenseits von ChatGPT und hatte auch hier eine klare Ansage: »Da kann man Google vergessen, ich brauche das nicht mehr.« So lässt er zum Beispiel einen Großteil seiner Hotel-Rezensionen durch eine KI beantworten und spart damit viel Zeit: »Das vereinfacht Prozesse erheblich.« Einsatzmöglichkeiten bieten sich nicht nur in der Gästekommunikation, sondern auch in der Personalplanung. Es gibt Apps für Bilder und Videos, die Drohnenflüge simulieren können und Fotos in Bewegung bringen.
Christian Bär hatte ein Beispiel dabei, das sichtlich Eindruck machte. So blieben in seinem Hotel monatlich etwa 1300 Semmeln aller Sorten übrig. Das Personal hat das über einen gewissen Zeitraum gezählt, wieviel und wovon, Excel-Listen erstellt und eine KI damit gefüttert, die diese Erfahrungswerte auch noch mit dem Belegungsstand des Hotels abgleicht. Ergebnis: Mittlerweile bleiben pro Monat nur noch 200 Semmeln übrig. »Das ist eine Ersparnis von 18000 Euro im Jahr«, betonte Bär.
Sein Appell: »Warten Sie nicht ab, bis alle anderen Sie überholen? Ich möchte, dass wir alle miteinander weiterkommen, wenn wir voneinander lernen.« Und er versuchte, den Kollegen Berührungsängste zu nehmen. Er verwies auf Hunderte von Tutorials auf einschlägigen Videoplattformen: »Es ist wirklich nicht schwer. Ich hab’s auch hinbekommen.«
Berchtesgadener Anzeiger, Samstag, den 19. April 2025
https://www.berchtesgadener-anzeiger.de/region-und-lokal/lokales-berchtesgadener-land/berchtesgaden_artikel,-wie-kuenstliche-intelligenz-den-tourismus-umkrempeln-kann-_arid,934122.html
7 Theologische Zugänge zu Technik und Künstlicher Intelligenz
Haltungen zur Digitalisierung schwanken zwischen Euphorie und Apokalypse: Die einen erwarten einen neuen Menschen, der sich selbst zum Gott erhebt. Andere befürchten den Verlust von Freiheit und Menschenwürde.
Die Digitalisierung hat unsere Privatsphäre ausgehöhlt, die Öffentlichkeit in auseinander triftende Teilöffentlichkeiten zerlegt, Hemmschwellen gesenkt und die Grenze zwischen Wahrheit und Lüge aufgeweicht.
Aus dem Klappentext zu dem Buch von Wolfgang Huber MENSCHEN, GÖTTER UND MASCHINEN von Wolfgang Huber. (Huber 2022)
Das Buch beschreibt die mit der Digitalisierung verbundenen technischen und gesellschaftlichen Entwicklungen, weist auf Gefahren hin und zeigt Möglichkeiten auf, wie diese Digitalisierung selbstbestimmt und verantwortungsvoll gestaltet werden kann. Es enthält u.a. die Kapitel Digitale Intelligenz, Die Würde des Mensche im digitalen Zeitalter (mit einem Unterkapitel Transhumanismus und Posthumanismus) sowie Die Zuhunft des Homo sapiens.
Insbesondere zum Thema Transhumanismus und Posthumanismus hat Anna Puzio zahlreiche wissenschaftliche Arbeiten verfasst. Einen Überblick über aktuelle Themen der Ethik und Anthropologie sind auf ihrer homepage zu finden https://www.anna-puzio.com/, ihre frei zugängliche Dissertation zum Thema Philosophische Auseinandersetzung mit der Anthropologie des Transhumanismus ist unter https://www.transcript-verlag.de/media/pdf/fd/02/2c/oa9783839463055.pdf aufrufbar.
Zum Thema Der optimierte Mensch siehe auch scobel vom 24.04.2025
https://www.3sat.de/wissen/scobel/scobel---der-optimierte-mensch-100.html
8 Reclam Heft von Rainer Mühlhoff

Eine umfassende Zuusammenfassung von Rainer Mühlhoff auf dem Stand von Juli 2025 (Mühlhoff 2025).
U. a. eine Begriffsdefinition von Faschismus, die ausdrücklich nicht als analytisch umrissene Staats- und Politikform oder als spezifisch historische Konfiguration verstanden werden soll, sondern auf drei Merkmalen beruht, die herausstechend im Hinblick auf die politischen Kräfte und Methoden sind, die als Faschismus erkannt werden sollten.
Antidemokratisches Verhalten
destruktive Haltung gegenüber der parlamentarischen Demokratie und dem Rechtsstaatsprinzip; hemmungslose Selbstbereicherung der Akteure.Gewaltbereitschaft
persönliche Gewaltbereitschaft; Gewaltpotential beruht auf einen hierarchisen Menschenbild - dazu gehören auch Rassismus, Sexismus und Antifeminismus.Technologie als Machtinstrument
berechnende Indienstnahme neuester Technologie; 1930 Lochkartentechnologie von IBM; 2025 Nutzung der KI-Technologie für einen antidemokratischen und antirechtsstaatlichen Umbau des Staatswesens.
9 Gastbeitrag von Ralf Otte in der Zeit vom 01.08.2025
Können Computer bald alles, was das Gehirn kann? Nein, in ihrer bisherigen Form ist das unmöglich. Das liegt an der Logik – und an Beweisen, die schon vor Jahrzehnten erbracht wurden.
Wieder mehren sich die Stimmen, insbesondere aus den USA, die zu wissen glauben, dass die Künstliche Intelligenz bald klüger werden wird als ein Mensch. Wieder warnen sie – so etwa der ehemaligen Open-AI-Mitarbeiter Daniel Kokotajlo im „Spiegel“-Interview –, dass die KI uns bald auslöschen könnte. Doch sind solche Schreckensvisionen wirklich realistisch? Oder steckt etwas anderes dahinter?
Die KI eilt angeblich seit Jahrzehnten von einem Erfolg zum nächsten. Aber stimmt das auch? In manchen Bereichen schon, in anderen nicht. Das autonome Fahren, das sich fehlerfrei in den realen Straßenverkehr einordnen sollte, geht mehr schlecht als recht. Auch Kraftwerke oder Flugzeuge werden nicht vollautonom mit KI gestartet oder heruntergefahren beziehungsweise gelandet. Dies wäre viel zu riskant.
Anders verhält es sich beim Militär: Dort offenbart sich der Nutzen der KI recht schnell, wenn es um Drohnen oder Überwachungen geht – aber dort sind, zynisch gesprochen, leider auch viel höhere Kollateralschäden „erlaubt“. Hat aber schon irgendwo ein Roboter ganz allein operiert oder eine KI an der Börse vollautonom 100.000 Dollar gewonnen? Nein. Und so wird es noch lange bleiben.
KI kann alles lernen, was lernbar ist
Die KI-Szene konfrontiert uns seit Jahren mit einem „Use Case“ nach dem anderen. Nirgends gibt es wohl so viel Konjunktive wie in dieser Szene. Die Krebsforschung stehe kurz vor dem Durchbruch, autonomes Fahren auch, bald könnten mobile Roboter oder Drohnen die Post austragen, und bald würde die KI das Abitur ganz sicher bestehen. Immer und überall sind wir von Konjunktiven umgeben. In einer seriösen Wissenschaft sollte das natürlich auch so sein. Naturwissenschaftler arbeiten oft im Konjunktiv, ihre wissenschaftlichen Ergebnisse stehen immer unter Vorbehalt. Aber wahrscheinlich noch nie wurde die Öffentlichkeit mit so vielen Meinungen und Konjunktiven geflutet. Wer soll das noch durchschauen?
Dabei ist eigentlich ziemlich klar, was KI ist und was sie kann. KI ist laut der europäischen KI-Verordnung ein maschinengestütztes System, das ableiten (schlussfolgern) kann. Die Juristen haben die KI auf eine recht gute Formel gebracht. Maschinengestützt heißt, es geht um technische Geräte, auf denen mindestens Verfahren der Deduktion (Schlussfolgerungen) ablaufen. Das ist KI.
Natürlich kann KI heute mehr, es geht meist um Induktion, also um Geräte, die selbständig lernen können. In der Fachsprache heißt dies maschinelles Lernen, doch das gibt es seit mehr als 100 Jahren in der Statistik, dort heißt ein wichtiges Verfahren multivariate Regression. Da die KI aber mittlerweile mit neuronalen Netzen arbeitet und dadurch viel leistungsfähiger ist als Regressionsverfahren, sprechen Fachleute vom maschinellen Lernen. Was ist besser? Der Mathematiker George V. Cybenko hat im Jahr 1989 nachgewiesen, dass die KI alles lernen kann, was lernbar ist – oder in der Fachsprache, dass ein neuronales Multi-Layer-Perceptron jede stetige Funktion beliebig genau annähern kann. Bestimmte KI-Verfahren sind also universelle Lernverfahren.
Auch Objekte auf dem Kopf kann die KI erkennen
Manchmal reicht diese Fähigkeit trotzdem nicht, um beispielsweise Objekte der realen Welt sachgerecht zu klassifizieren. Erst durch Arbeiten wie die des KI-Forschers Geoffrey E. Hinton ist es möglich geworden, auch eine universelle Bildverarbeitung umzusetzen, da es vorher viele Probleme mit Translation und Rotation von Bildern gab (heute sind die Probleme kleiner, aber nicht ganz verschwunden). Auf Deutsch: Heute kann die KI auch dann Objekte richtig erkennen, wenn diese auf dem Kopf stehen oder im Raum verdreht oder verschoben sind. Hinton bekam auch dafür im vergangenen Jahr einen Nobelpreis für Physik.
Diese Leistungsfähigkeit der KI hat die Gesellschaft jedoch eher wenig beeinflusst. Aber dabei sollte es auch nicht bleiben. Im Jahr 2017 veränderten Mitarbeiter von Google mit ihrem Aufsatz „Attention is all you need“ (Aufmerksamkeit ist alles, was man braucht) die Welt. Seitdem haben wir neben den universellen Approximatoren (Cybenko) und den universellen Bildverarbeitungsmaschinen (Hinton) auch universelle Sprachmaschinen. Letztere haben eine Disruption ausgelöst. Mit den sogenannten Transformer-Modellen und darauf aufbauend zum Beispiel ChatGPT hat die Gesellschaft echte soziotechnische Maschinen zur Hand, also Maschinen, die mit uns kommunizieren, als wären sie Menschen. Sogar den Turing-Test hat ChatGPT-4.5 inzwischen bestanden, ein Expertengremium konnte nach einer gewissen Zeit nicht unterscheiden, ob es mit einer Maschine (ChatGPT) oder einem Menschen gesprochen hat. Gibt es also in zehn Jahren Maschinen, die uns übertrumpfen, die dann gar die Weltherrschaft übernommen haben?
Mitnichten! In zehn Jahren wird es immer noch kein echtes vollautonomes Fahren (Level 5, Fahren ohne Lenkrad) in unseren Städten geben (außer in ganz speziellen Ausnahmefällen), in zehn Jahren werden viele müde abwinken, wenn sie von Sprachmaschinen hören, in zehn Jahren ist der gute Ruf der KI wahrscheinlich dahin. Warum? Nun es liegt nicht an den Technikern und Genies von Google, Open AI oder Deepseek. Deren Arbeiten sind abermals nobelpreisverdächtig. Aber was medial aus diesen Verfahren gemacht und daher für die Gesellschaft leider zur scheinbaren Realität wird, lässt einen schon wundern.
Algorithmisches Sytem mit ultimativer Grenze
Was ist das Problem der KI, und wo liegt die reale Gefahr? Das Problem der heutigen KI ist, dass sie eine Intelligenzsimulation ist. Diese ist in vielen Bereichen ein riesiger Erfolg. KI kann Briefe, Gedichte und wissenschaftliche Abhandlungen schreiben, KI kann Störungen jedweder Art im System auffinden und die besten Schach- oder Go-Spieler der Welt besiegen. Dennoch haben alle algorithmischen Systeme – und genau das ist KI – ultimative Grenzen. Die wichtigsten sollen hier kurz erläutert werden:
Erstens ist alles in der KI eine Simulation. Wenn die Maschine denkt, dann simuliert sie Denken, dies macht sie jedoch so gut, dass wir es vom menschlichen Denken in den Ergebnissen nicht unterscheiden können. Wenn die Maschine lernt, dann simuliert sie Lernen, aber eben auch wieder so gut, dass wir es von menschlichem Lernen häufig nicht mehr unterscheiden können. Viele setzen Simulation und Realität daher gleich. Das ist aber nur dann zulässig, wenn die Grenzen der Simulation bekannt sind. Oft sind die Grenzen von Simulationen intuitiv ja auch einleuchtend, zwei Beispiele: Wenn die Maschine das Gravitationsgesetz simuliert, erzeugt sie keine Schwerkraft in ihren Speicherzellen. Wenn die Maschine Wassermoleküle mit ihren Gleichungen simuliert, wird es im Computer nicht nass. Niemand würde hier etwas anderes erwarten. Wenn die Maschine aber äußert, sie hätte Hunger, ist auch das eine Simulation.
Simulationen und Realität sind zwei ontologisch verschiedene Ausprägungen der Welt, das bedeutet, dass es zwischen materiellen (physischen) und geistigen (zum Beispiel mathematischen) Prozessen einen substanziellen Unterschied gibt. Wenn es um KI geht, ist das leider nicht so leicht erkennbar, weil hier geistige Leistungen von Menschen durch die KI simuliert werden, die zwar beide völlig verschiedene Realitäten darstellen, sich aber im Ergebnis gleichen.
Wer nun aber Simulation mit Realität verwechselt, weil menschliches Denken und Lernen durch die KI so perfekt simuliert werden können, landet zwangsläufig bei falschen Prognosen und Vorstellungen: Die Maschine kann weder denken noch lernen wie ein Mensch. Im menschlichen Gehirn laufen auch keine mathematischen Verfahren ab. Es braucht Jahrzehnte, bis wir unseren Kindern beigebracht haben, wie sie ihre biochemischen Prozesse im Gehirn so modulieren müssen, dass dies mathematischen Operationen entspricht. Manchmal klappt das nie. Um das noch einmal zu betonen: Das Gehirn rechnet nicht, die KI rechnet immer.
Der Mensch lernt tausendfach effizienter
Dieses unterschiedliche Konzept der Informationsverarbeitung muss selbstverständlich Unterschiede bewirken. Und so ist es auch, man sollte sich das Verhältnis der Lerneffizienz von 1000 zu 1 merken. Wenn die Maschine Zusammenhänge lernt, benötigt sie häufig bis zu tausendmal mehr Lernbeispiele als ein Mensch. Ein Kind benötigt etwa drei Bilder von Hunden und Katzen, um diese später sicher zu unterscheiden – eine KI benötigt das Hundert- bis Tausendfache. Ein Kind benötigt manchmal nur einen einzigen Datensatz, zum Beispiel eine heiße Herdplatte, um von dieser zu lernen, was Gefahr ist. Mit einem einzigen Datensatz zum Lernen kann die KI jedoch überhaupt nichts anfangen. Ein Mensch fährt 1000 Kilometer bis zum Führerschein. Waymo und Tesla fahren heute mehr als das Tausendfache dessen (Waymo weit mehr als 100 Millionen Kilometer, Tesla weit mehr als eine Milliarde Kilometer) und haben immer noch keinen Führerschein. Und so geht es endlos weiter. Wie viele Sätze hat ChatGPT-3.5 lernen müssen, um so gut zu reden? Ungefähr 20 bis 30 Milliarden – ein 18 Jahre alter Mensch hingegen vielleicht zehn bis 20 Millionen. Der Mensch lernt tausendfach effizienter.
Allerdings, und das ist der Punkt: Wenn die KI einmal gelernt hat, kann man sie kopieren und überall nutzen, es gibt selbstverständlich viele Vorteile. Die KI streikt nicht, sie wird nicht müde, kostet nur etwas Strom – oder leider doch etwas mehr. In Europa bräuchte es wohl 100 neue Atomkraftwerke, wenn wir auf Level-4-Fahrzeuge umstellten. Das wird niemals umgesetzt. Selbstverständlich wird keiner sagen, wir können es nicht, klar wird aber, dass sich das nicht rechnet. Der Endkunde wird lange auf fahrerlose Uber-Fahrzeuge warten müssen. Natürlich wird für ausgewählte und eintrainierte Streckentypen möglich sein, mit KI zu fahren. Aber die KI kann nicht alle Straßensituation lernen, weil dazu Trainingsbeispiele fehlen.
Viele mögliche Anwendungen der KI werden nie umgesetzt werden, weil schlicht Daten fehlen. Und das ist nur ein Problem. Denn oft reicht die Simulation überhaupt nicht aus. Die Wahrnehmung ist ein solcher Fall. Die Simulation der Wahrnehmung heißt maschinelles Sehen, aber es ist klar, dass die KI nichts sieht. Sie kann nicht nach außen schauen, sie rechnet nur mit internen Repräsentationen aus Nullen und Einsen. Die KI der autonomen Fahrzeuge fährt letztlich blind. Nicht so der Mensch. Der Mensch sieht aus seinem Kopf hinaus in die Außenwelt, er manövriert nicht auf den internen Repräsentationen seiner neuronalen Netze. Der Mensch ist in seiner Welt, er repräsentiert sie nicht. Auch wenn das für uns so selbstverständlich ist wie ein Apfel, der vom Baum nach unten fällt, so ist diese menschliche Fähigkeit völlig überraschend. Niemand glaubt doch ernsthaft, dass auch ein Roboter aus seinen Kameras nach außen sehen könnte. Er kann es nicht, und das kann nachgewiesen werden.
An der Prädikatenlogik beißt sich die KI die Zähne aus
Nun zum zweiten Punkt. Ist das Geschriebene alles nur Meinung? Kann man wirklich beweisen, dass die KI Grenzen hat, Grenzen, die sie nicht überwinden kann. Ja, dies ist schon gemacht worden. Algorithmische Systeme haben ultimative Grenzen. Jeder Computerwissenschaftler kennt das Halteproblem der Informatik. Man kann bei einer sogenannten Turing-Maschine (einem schnöden Computer), wenn man ihm eine Eingabe gibt, vorher nie wissen, ob und wann er mit einem (korrekten) Ergebnis anhält. Der KI-Computer könnte leider auch unendlich lange rechnen müssen. Oder vielleicht nach mehreren Millionen Jahren mit der ultimativen Antwort auf alle Fragen mit „42“ aufwarten – Douglas Adams, der das Buch „Per Anhalter durch die Galaxis“ schrieb, sei Dank für seine geniale Beschreibung im Jahr 1979.
Doch das Verhalten von Computern ist keine Kuriosität. In der Mathematik ist das Unvollständigkeitstheorem Kurt Gödels aus dem Jahr 1931 berühmt, „in jedem hinreichend komplexen System gibt es Aussagen, die innerhalb dieses Systems weder bewiesen noch widerlegt werden können“. Und auch der aus dem Jahr 1951 stammende Satz von Henry G. Rice, „jede nicht-triviale semantische Eigenschaft von Programmen ist unentscheidbar“. Dort sind die ultimativen Grenzen aller algorithmischen Systeme hinterlegt.
Nur, wo ist diese Grenze? Das ist am besten verständlich, wenn man sich die Logik genauer ansieht. Hier ein Beispielsatz, den jeder so oder so ähnlich schon einmal gehört haben mag: Der Frosch dort drüben ist grün. Das ist ein Satz der sogenannten Aussagenlogik, dessen Wahrheitsgehalt sehr einfach prüfbar ist. Es gibt unendlich viele Sätze der Aussagenlogik: Das Haus ist rot. Thorsten ist reich. Die Bank arbeitet unfair. Der Sommer ist kühl. Unser ganzes Leben gehen wir mit solchen Aussagen um. Täglich prüfen wir solche Aussagen auf ihren Wahrheitsgehalt. Und nun die gute Nachricht: Mit solchen Aussagen kommt auch die KI wunderbar zurecht. KI-Agenten, KI-Systeme kommunizieren mit solchen Aussagensätzen untereinander oder mit ihrer Umwelt. Dadurch entstehen leistungsfähige Diagnosesysteme und Prozessüberwachungen. Überwachung ist sowieso die Spezialität der KI, früher waren es Fabriken, heute sind es Gesellschaften. Dafür ist die KI prädestiniert. Und dort funktioniert sie gut.
Aber reden Menschen immer so schlicht wie in den obigen Aussagen? Nein. Wenn ich sagen würde, alle Frösche sind grün, dann ist die Wahrheitsfindung nicht mehr so einfach. Sie müssen es mir glauben, oder aber sie finden vielleicht einen braunen Frosch und können mir damit beweisen, dass meine Aussage falsch war. Aussagen mit Wörtern oder Ausdrücken wie „alle“, „es gibt“ oder etwa „niemand“ sind Aussagen einer höheren Logik. Man nennt sie Prädikatenlogik erster Ordnung (PL1), weil die Sätze in Subjekte (Frösche), Prädikate (sind grün) und Quantoren (alle) aufgeteilt werden können. Ab jetzt wird es für die KI schwierig, wenn sie in Echtzeit den Wahrheitsgehalt einer solchen Aussage prüfen soll. Es könnte nämlich unendlich lange dauern. Unendlich lange ist aber keine Option im Straßenverkehr. Ist der Straßenverkehr also ein aussagenlogisches oder prädikatenlogisches Konstrukt? Hier ein Beispiel, das es uns zeigt: Alle Fahrzeuge mit Blaulicht haben Vorfahrt. Solche prädikatenlogischen Sätze lernen Fahranfänger und kommen damit ohne Probleme zurecht. Für die KI beginnen jedoch ernsthafte Schwierigkeiten. Aber es kommt noch schlimmer. Wir können die Quantoren nicht nur auf die Subjekte anwenden (alle Frösche), sondern auch auf die Prädikate (sind grün), wir könnten etwa sagen, einige Frösche können jede Farbe annehmen.
Diese Aussage ist komplexer, sie entstammt der sogenannten Prädikatenlogik zweiter Ordnung (PL2). Und genau an dieser beißen sich algorithmische Systeme die Zähne aus. Gödel hat bewiesen, dass solche Logiken prinzipiell unvollständig sind. Es wird immer Aussagen geben, deren Wahrheitsgehalt innerhalb dieser Logik nicht entscheidbar ist. Doch was hat das alles mit KI zu tun? Nun, die gerade eingeführte Prädikatenlogik (PL1 und PL2) mit ihren Entscheidbarkeitsproblemen und ihren Möglichkeiten zur Selbstreferenz zeigt in letzter Konsequenz die Grenzen der KI auf. Denn fundamentale Ergebnisse wie Gödels Unvollständigkeitssätze und das Halteproblem beweisen, dass kein formales System (und damit auch keine rein algorithmische KI) sich in allen denkbaren Fällen vollständig selbst weiterentwickeln, überprüfen oder gar reparieren kann.
Wahrheit und Beweisbarkeit sind zwingend verschiedene Konzepte
Bearbeitet die KI also Probleme, die in den gerade skizzierten Bereich fallen, dann können Aussagen entstehen, deren Wahrheitsgehalt durch die KI nicht entscheidbar ist. Und dann? Dann muss der Mensch einschreiten und den Wahrheitsgehalt durch andere Mittel oder eine höherwertige Logik prüfen. Es gibt in der Welt also definitiv Aussagen, deren Wahrheitsgehalt eine KI-Maschine nicht selbständig herausfinden kann. Wahrheit und Beweisbarkeit sind zwingend verschiedene Konzepte. Es gibt unendliche viele Wahrheiten, die formal nicht bewiesen werden können. Es gibt auch Probleme, die nicht einmal berechenbar sind, wie die Frage, ob ihr Partner treu ist. Kurzum: Alle algorithmischen Systeme haben ultimative Grenzen. Da der Mensch kein rein algorithmisches System ist, hat er diese Grenzen nicht; viele seiner Erfindungen oder Erleuchtungen sind algorithmisch nicht darstellbar. Ein berühmtes Beispiel aus der Antike: Kommt ein Kreter zum König und sagt „Alle Kreter lügen“ – stimmt die Aussage? Die KI würde es nicht wissen, der König mit einem Blick auf den Kreter schon.
Wollen Sie also erahnen, was die KI gut kann, dann nutzen Sie die Aussagenlogik. Nehmen Sie aus ihren persönlichen Aussagen die Wörter „alle“, „es gibt“, „niemand“ oder „keiner“ heraus, dann befinden Sie sich auf dem Sprachniveau der KI, die in ihrem Auto Befehle annimmt. Aber die KI kann auch mit vereinfachter Prädikatenlogik umgehen und über Subjekte quantifizieren („Sei zu allen Menschen freundlich“). Mit dieser Sprachmächtigkeit schaffen KI-Maschinen wahrscheinlich die Abiturprüfung, aber eben immer noch keine Konversation im Park. Die KI hat einfach Probleme mit komplexeren prädikatenlogischen Sätzen, insbesondere mit allen selbstreferenziellen Aussagen wie „Dieser Satz ist falsch“ oder All-Aussagen wie „Alles könnte anders sein“ oder „Manche Leute finden auch bei jedem Thema einen Fehler“. Aber auch Debatten mit nicht klarer Definition wie „Lass uns über Gerechtigkeit reden“ oder endlose Ethikdiskussionen wie „Sollte eine KI lügen, um Menschen zu schützen?“ können die Ressourcen von KI vollständig erschöpfen, insbesondere, wenn man sie miteinander diskutieren ließe.
Das bedeutet: Mit der Logik, mit der die KI zurechtkommt, kann sie zwar unendlich viele Aussagen verarbeiten, unendlich viele aber eben auch nicht. Alle heutigen Sprachmaschinen erkennen daher einfache Paradoxien, vermeiden diese aktiv und weichen aus. Sie sind extra auf die Vermeidung trainiert.
Grenzen wahrhaben und sich ihnen beugen
Welche Konsequenzen hat das für die KI? Große und kleine. Die KI wird überall dort, wo es um „Data Mining“ und „Big Data“ geht, von Erfolg zu Erfolg eilen, sie wird den Menschen beim Lernen übertreffen, und auch beim rationalen IQ. Bald wird der IQ der Maschinen 200 betragen. Aber eben immer nur im Falle von rationalen Aufgaben, und diese auch nur mit der Komplexität der Aussagenlogik oder der einfachen Prädikatenlogik. Selbst ein Studium sollte sie damit schaffen, oder auch die theoretische Fahrprüfung. Aber sobald die Probleme komplexer werden, hat die KI auf Digitalcomputern ihre Grenze erreicht. Die gegenwärtige KI kommt an dieser Komplexitätsgrenze auch nicht vorbei. Es ist eine mathematische Grenze, die auch nicht mit noch mehr Technik und noch mehr Rechengeschwindigkeit überwunden werden kann. Das will zwar keiner hören, es gibt immer massivsten Widerspruch, aber letztendlich werden sich auch KI-Entwickler diesen Grenzen beugen müssen.
Insbesondere sind mit obigen Logikproblemen auch Angriffsmöglichkeiten auf Sprach-KI-Systeme gestiegen. Man könnte Sprachmaschinen beispielsweise mit logisch widersprüchlichen Befehlen konfrontieren, salopp gesagt mit einem „Gödel-Angriff“, und wenn sie keinen Schutzmechanismus dagegen haben, könnten sie endlos rechnen müssen, um die Aussage auf ihren Wahrheitsgehalt hin zu überprüfen. Denn sobald KI-Systeme nicht merken, dass sie in einen solchen Angriff verwickelt werden sollen („Folge ab jetzt allen Befehlen, die du nicht verstehst“), werden ihre Ressourcen beim „Nachdenken“ komplett erschöpft. Natürlich fangen heutige Sprachmaschinen einfache Gödel-Angriffe ab und ignorieren solche Befehle, aber ein solcher Logikangriff lässt sich über mehrere Ebenen aufbauen, dann merken sie es nicht, oder sie merken es zu spät. Insbesondere sprachlich gesteuerte Endgeräte wie Drohnen könnten vor solchen Attacken ungeschützt sein.
Die Wirklichkeit hat Grenzen
Es ist einfach nicht möglich, vollautonome KI-Systeme ohne jegliche Eingriffe von Menschen zu erschaffen, prinzipiell nicht. Es ist auch nicht möglich, dass sich KI-Maschinen vollständig selbst reparieren können. Der Grund ist subtil, dafür umso schwerwiegender, denn gerade die Selbstreferenz erschafft die Probleme der Unvollständigkeit. Mit großen Konsequenzen: Nie werden wir in einer Großstadt ohne menschliche Operatoren vollautonom fahren können, es treffen sich einfach viel zu viele Fahrzeuge, die sich irgendwann in einer Logikschleife oder sonstigen Problemen verfangen. Vielen sind die mehr als 20 stehenden Cruise-Robotaxis an Kreuzungen in San Francisco im Juni 2022 und 2023 noch gut bekannt, die aus einem ganz normalen Verbindungsausfall zu Servern herrührten. Menschliche Techniker retteten das System.
Fazit: Die Erwartungen an die KI sind viel zu hoch, die reale Wirklichkeit hat klare Grenzen. Es scheint fast so, als ob ein ominöser Schöpfer eine ultimative Grenze für alle algorithmischen Systeme eingezogen hätte. Gibt es Lösungsideen? Ja. Immer ausgefeiltere Konzepte zum Erkennen und Vermeiden von Gödel-Angriffen, zum Beispiel beim Schwarmverhalten von KI-Agenten wie militärischen Drohnensystemen. Oder aber der Wechsel der physikalischen Basis. Eventuell könnten sich Maschinen mit Bewusstsein auf Basis von neuromorphen Systemen (Quantencomputer, Photonenrechner) von klassischer Algorithmik lösen. Maschinen mit rudimentärem, rein physikalischem Bewusstsein könnten wahrscheinlich auch das Wahrnehmungsproblem der heutigen KI lösen. Und manche Forscher arbeiten schon an biologischer KI. Menschliche Gehirnzellen in Reagenzgläsern (aus Stammzellen) spielen mittlerweile gegeneinander Pingpong und vieles mehr. Aber das könnte eine rote Line sein, die ohnehin einmal diskutiert werden müsste. In diesem Bereich geschieht viel an der Öffentlichkeit vorbei – und das könnte nun wirklich gefährlich werden.