1 Einleitung
Es gibt eine Reihe von Datensätzen, die immer wieder als Beispiel verwendet werden, um damit die Leistungsfähigkeit statistischer Methoden und geeigneter Software zu demonstrieren.
Zu den berühmtesten derartigen Messwerten gehören sicher die Iris Daten von R.A Fisher. Christopher Wylie (bekannt als Whistleblower von Cambridge Analytica) schreibt in seinem 2020 erschienenen Buch MINDF*CK (Wylie 2016)
Ich brachte mir die Nutzung von grundlegender Software wie MATLAB und SPSS bei, die es mir erlaubte, mit Daten herumzuspielen. Statt ein Handbuch zu konsultieren, begann ich, mit dem Iris-Datensatz zu experimentieren - dem klassischen Datensatz für jeden Statistikanfänger-, und wandte die Trial-and-error-Methode an. Die Möglichkeit der Datenverarbeitung unter Verwendung der verschiedenen Merkmale der Iris, wie Farbe und Länge des Blütenblatts (Anmerkung: eigentlich Breite und Länge von Kelch- und Blüten-Blatt), die Blumenart zu identifizieren schlug mich völlig in den Bann.
Ein weiterer oft benutzter Datensatz - meist zur Demonstration von statistischen Verfahren zur gleichzeitigen Analyse von zwei Datenmatrizen - ist der Olivenöldatensatz (Siehe auch den Blog: Procrustes anaysis).
Daten von Genussmitteln werden offensichtlich gerne analysiert; so auch ein Datensatz über whiskey Geschmacksprofile - erhoben von der Universität Strathclyde.
2 Beschreibung der whiskey Daten
Der wesentliche Teil der whiskey Daten umfasst die Bewertung von 86 Malt-Whiskies bezüglich 5 verschiedener Geschmackskategorien:
- Body
- Smoky
- Fruity
- Floral
- Winey
Body: A whisky is described as “full-bodied” when it has a complex flavour profile. Depending on the types of casks and the duration they are aged, whiskies produced can end up having more than one dominant flavour. That is what whisky lovers mean by their drink being full-bodied. For example, a rich and rounded whisky like the Singleton of Glen Ord 15 Years Old reveals hints of melons at its own very elegant pace. On the other hand, “light-bodied” whiskies tend to have one clear flavour note. Whiskies that are described as “light” or “light-bodied” tend to have a clearer and fresher taste. Some of these whiskies remind you of dried fruits, while others have a really clean floral smell. To get a light bodyweight, the whisky will need to be distilled many times. This will also give the whisky its fruity note.
Smoky: When someone describes a whisky as “smoky”, they most probably mean that it tastes a little ‘burned’. Whisky gets its smokiness from peat, which is what the distilleries use to heat the barley at the final stage of the malting process. Naturally, the smoke will rise and cover the barley, giving it a nice smoky flavour. Whiskies distilled in the Highlands, Islands, and Islay regions are known for its peaty and smoky flavours. Peat is the main fuel source in these regions, especially in Islay, as it can be found almost everywhere.
Fruity: This is a very delicate flavour and is usually more noticeable in lighter whiskies. Take a sip of it and roll the whisky around your mouth. Try to connect what you’re tasting to some flavours you’re familiar with. If you can taste flavours that remind you of berries, oranges, or even apples, you could describe the whisky as “fruity”. If fruity whiskies are your thing, then you should look out for single malt Scotch produced in the Speyside and Highland regions.
Floral: You usually detect this smell before tasting the whisky. Does it smell like a bouquet of flowers, a garden, or even grass? That’s what your drinks expert friend refers to as the “floral notes”. Light and delicate whiskies have a more prominent floral note, which is common in whiskies produced in the Lowlands region.
Winey: Essence leached from ageing in a barrel previously filled with wine (often sherry or port). This includes tanins, fruit particulate, and other residues.
Weitere Kategorien sind:
- Sweetness
- Medicinal
- Tobacco
- Honey
- Spicy
- Nutty
- Malty.
Die Bewertunng erfolgt auf einer Skala mit den Werten 0, 1, 2, 3, 4.
Außerdem sind die räumlichen Koordinaten der 86 Destillerien sowie deren Zugehörigkeit zu den schottischen Whisky-Regionen erfasst.
An der Universität Strathclyde wurde dieser Datensatz mit Hilfe graphentheoretischer Methoden analysiert (Ergebnis: ein Netzwerk aus 493 Kanten bei 86 Knoten).
2.1 Analyse der Daten im DATA SCIENCE BLOG
Eine Analyse dieser Daten ist im DATA SCIENCE BLOG als post von Mathias Döring zu finden mit dem Titel: Dimensionality Reduction for Visualization and Prediction.
Im Vordergrund dieser Analysen steht das Problem der Dimensions-Reduktion. Wie können mulivariate Daten (z.B. die 12 Geschmackskategorien der Whisky-Daten) in niederen Dimensionen (vorzugsweise zweidimensional) dargestellt werden? In diesem post werden im wesentlichen drei derartige Methoden verglichen: Hauptkomponentenanalyse (PCA), KernelPCA und t-SNE. Im folgenden wird nur auf den ersten Teil: Visualisierung der whisky Daten mittels PCA Bezug genommem.
2.2 Anmerkung zur Reproduzierbarkeit
Die Reproduktion von Ergebnissen aus dem DATA SCIENCE BLOG ist erwartungsgemäß leicht möglich. Das Problem der Reproduzierbarkeit von wissenschaftlicher Arbeit ist jedoch generell ein großes Problem. Dies zeigt sich gerade wieder in Zusammenhang mit epidemiologischen Studien zum Themenkreis Corona. Dabei ist zu unterscheiden zwischen der Reproduzierbarkeit der Erhebung der Daten (z.B. Design einer Studie, Durchführung von Experimenten) und der Auswertung der erfassten Daten (z.B. apriori Auswertungskonzept, statistische Methodik, benutzte Auswertungssoftware ).
Dazu einige Anmerkungen von Nicholas Thierney aus: RMarkdown for Scientists Nicholas Tierney
We are in a crisis at the moment where a lot of people cannot reproduce scientific work. This isn’t just a few people, and it’s not cheap. Estimates say that in the biomedical industry, in the USA, irreproducibility (not being able to reproduce a given piece of work) costs $28 Billion dollars annually.1 That’s one country, one field, and one year.
Notably, in the R ecosystem, the Sweave (S+weave) program provided a way to write text and code together. It uses a form of LaTeX, which provides great flexibility at the cost of complexity to produce pdf-files. In 2004, John Gruber, of daring fireball created Markdown, a simple way to create text that rendered into an HTML webpage. Rmarkdown provides an environment where you can write your complete analysis, and marries your text, and code together into a rich document. You write your code as code chunks, put your text around that, and then hey presto, you have a document you can reproduce.
Die zweite Aussage bezieht sich nur auf den Teil der Daten auswertung. Das - meiner Meinung nach - wichtigere Ereignis war die Möglichkeit, mittels R (RSudio), Sweave und LaTex vollständige Texte mit live erzeugten Tabellen und Abbildungen zu erstellen. Damit ist auch die vollständige Reproduzierbarkeit garantiert. Obwohl diese Möglichkeit schon länger besteht, wird sie noch viel zu selten benutzt. Nur wenige wissenschaftliche Zeitschriften verlangen bisher die Existenz eine derartigen Dokuments. Damit könnte auch ein wesentlicher Beitrag zur Lösung des peer review Problems geleistet werden (Diese wenig angesehene Tätigkeit würde dann vereinfacht und von Detektivarbeit befreit werden.)
Natürlich bieten die neueren web-basierten Möglichkeiten mittels RMarkdown oder Quarto HTML-files zu erstellen ein Vielzahl von interessanten zusätzlichen Anwendungen und können damit zu einer weiteren Verbreitung wissenschaftlicher Arbeiten beitragen.
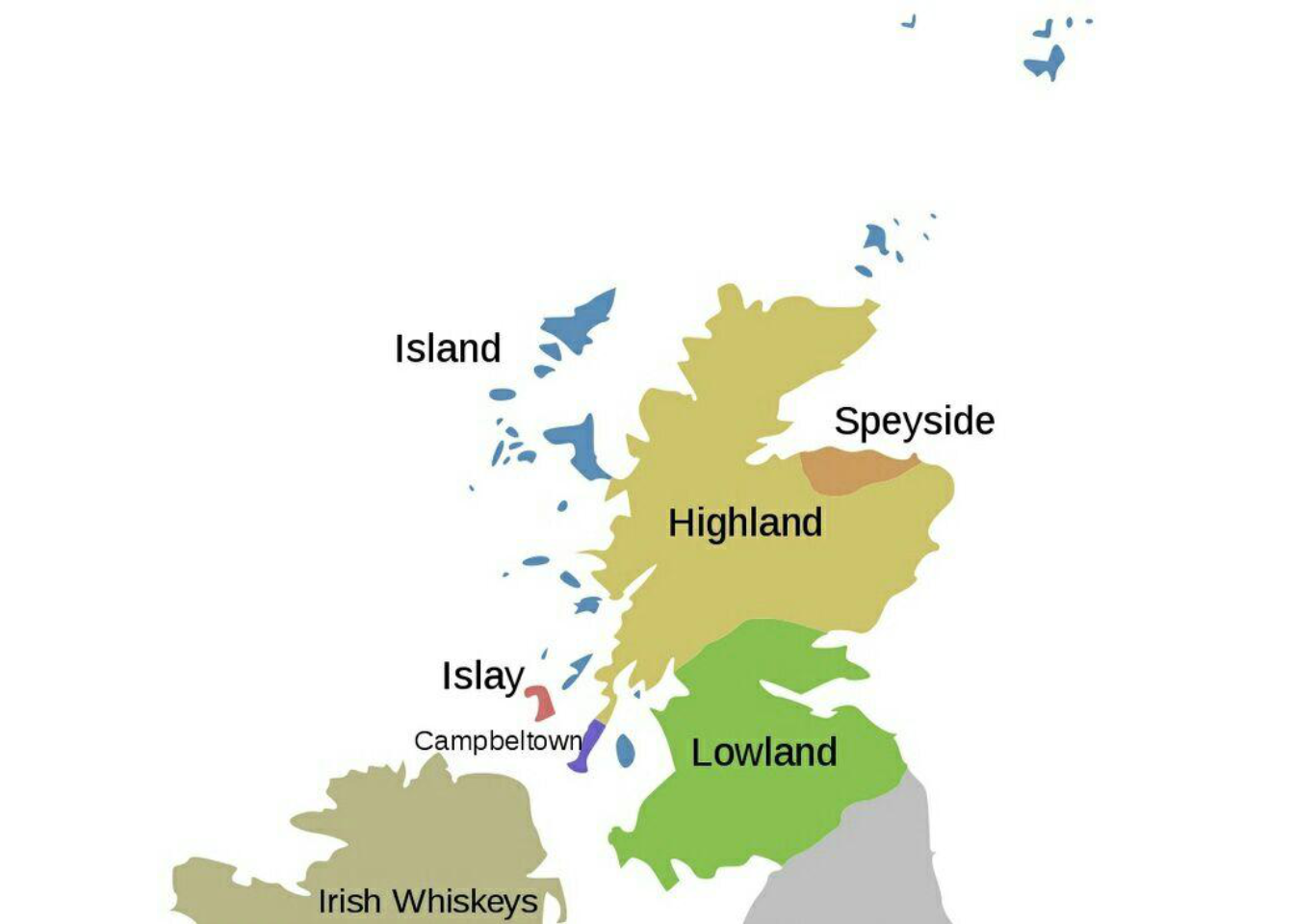
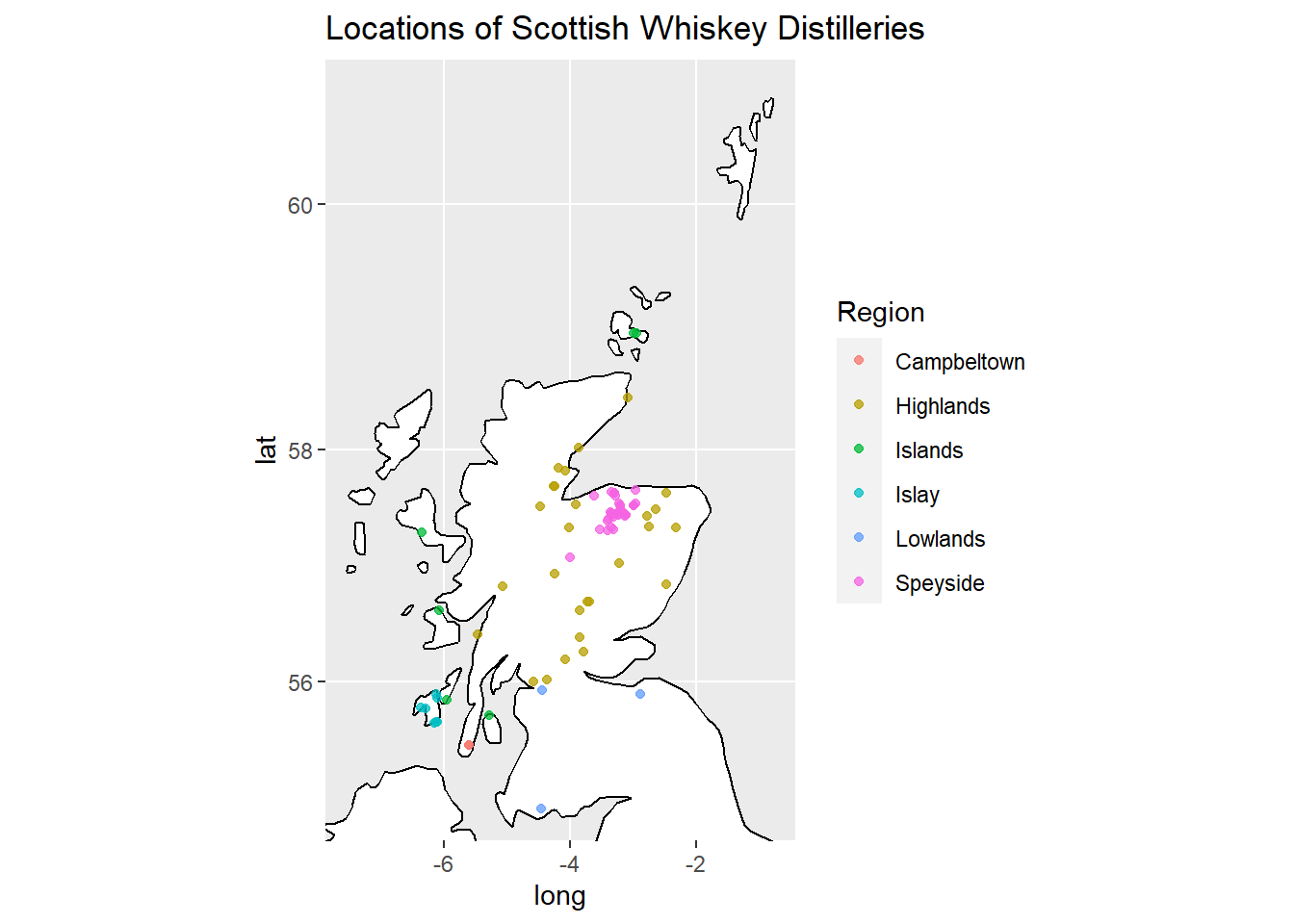
2.3 Beschreibung der räumlichen Verteilung der Destillerien
Die folgenden Abbildungen zeigen die räumliche Anordung der sechs schottischen Whiskey Regionen sowie die Lage der 86 Destillerien.Sie sind direkt dem post von M. Döring entnommem und können problemlos unter Verwendung von RStudio und RMarkdown reproduziert werden.
2.4 Dimensionsreduktion mittels Hauptkomponentenanalyse (PCA)
Die Analyse im DATA SCIENCE BLOG steht unter dem Oberbegriff der Dimensionalitätsreduktion.
Dimensionality reduction has two primary use cases: data exploration and machine learning. It is useful for data exploration because dimensionality reduction to few dimensions (e.g. 2 or 3 dimensions) allows for visualizing the samples. Such a visualization can then be used to obtain insights from the data (e.g. detect clusters and identify outliers). For machine learning, dimensionality reduction is useful because oftentimes models generalize better when fewer features are used during the fitting process.
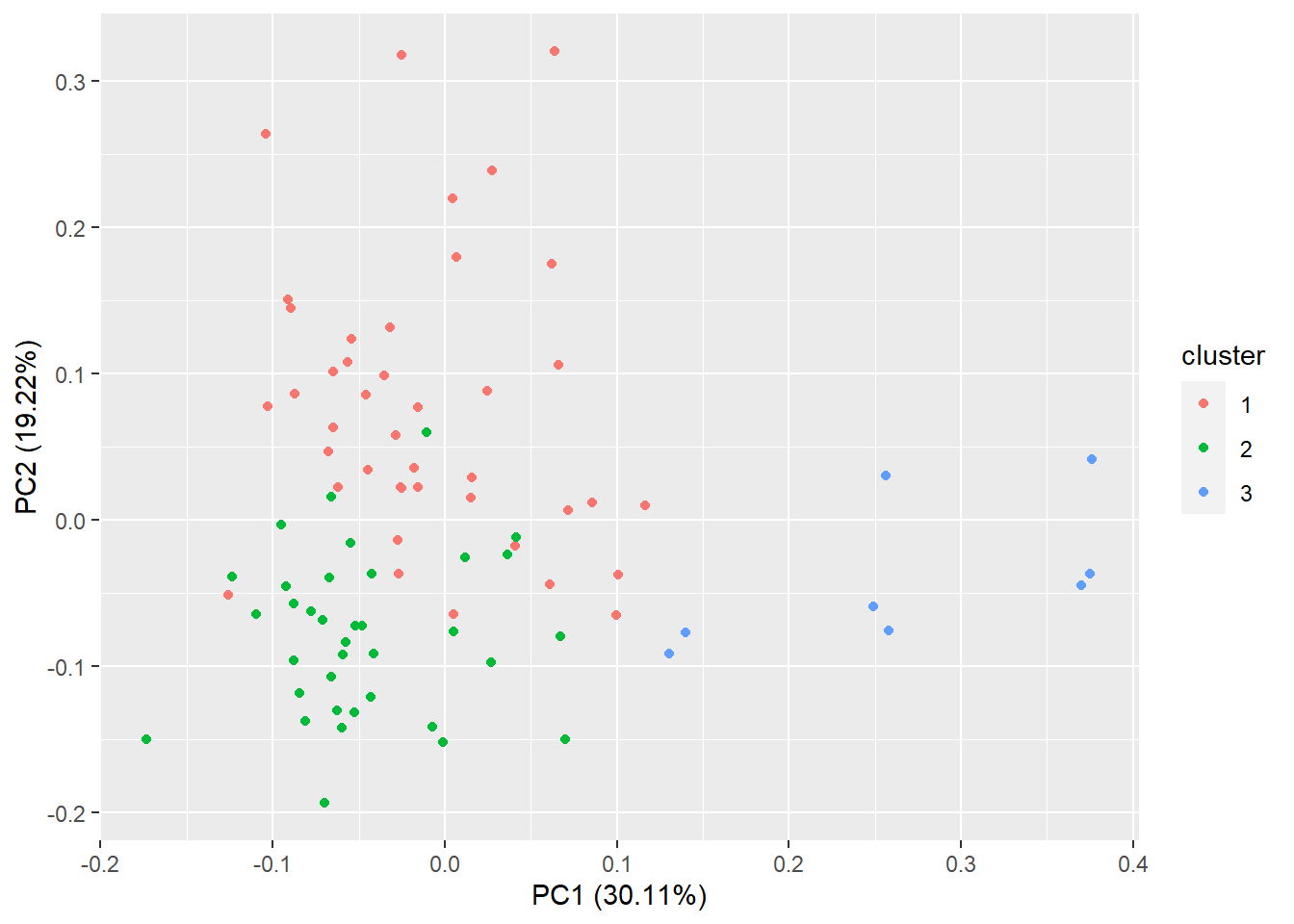
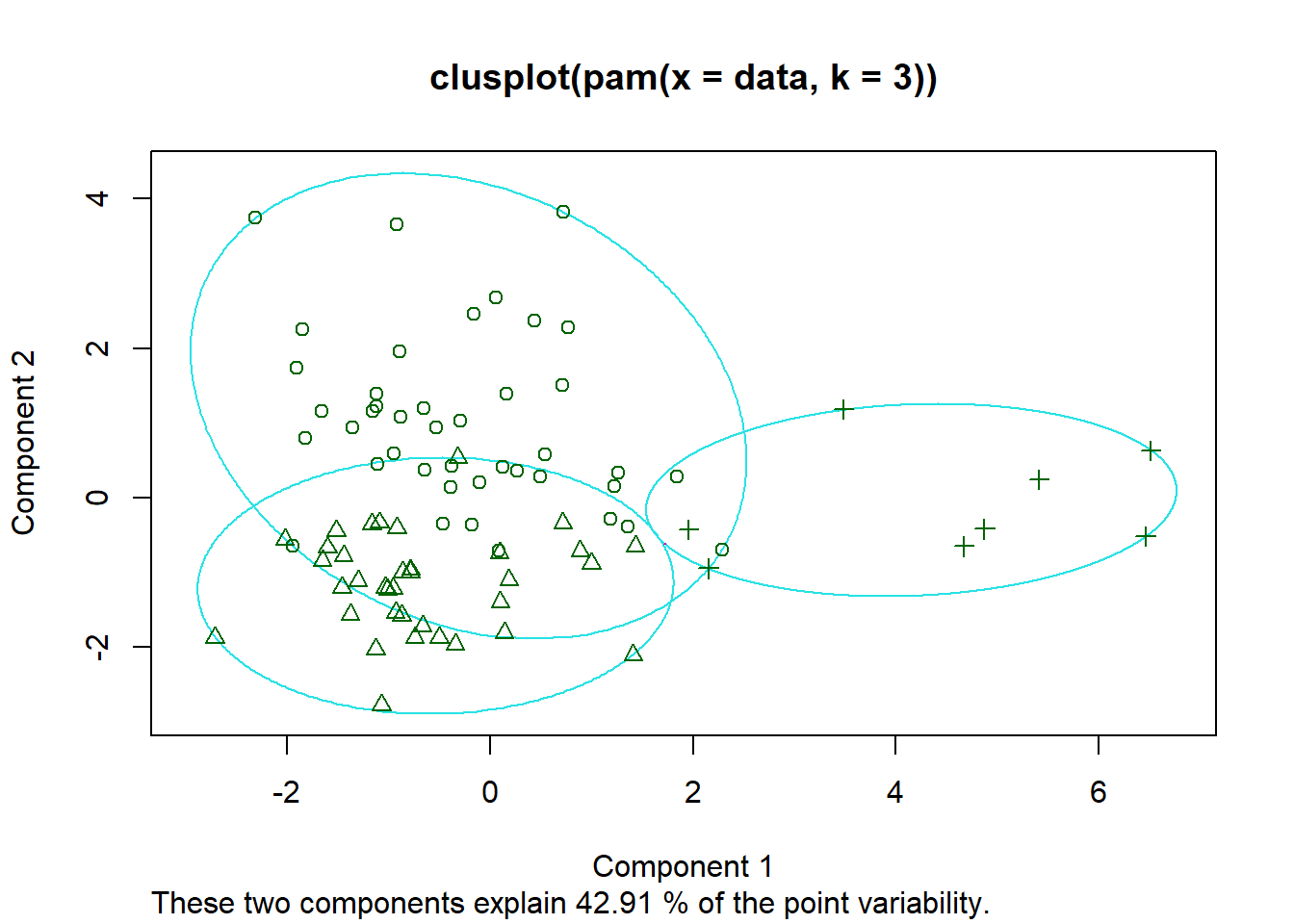
Zur Durchführung einer PCA wird normalerweise eine Funktion wie prcomp verwendet. In dieser Analyse wird jedoch autoplot aus dem R package ggplot2 benutzt. Mit den autoplot Funktionen sollen für jeden Datentyp mit einem einzigen Kommando bessere default Grafiken schnell und einfach erstellt werden können. Dazu ist meist nur die Angabe des Datensatzes und einer Auswertungsmethode nötig. Mit der Begründung primär an der Visualisierung der Daten interesiert zu sein, wird hier eine Clusteranalyse (Funktion pam, partitioning around medoids) benutzt; zur Visualisierung wird automatisch eine PCA durchgeführt (lediglich die Ausgabe der Biplot-Vektoren muss angefordert werden).
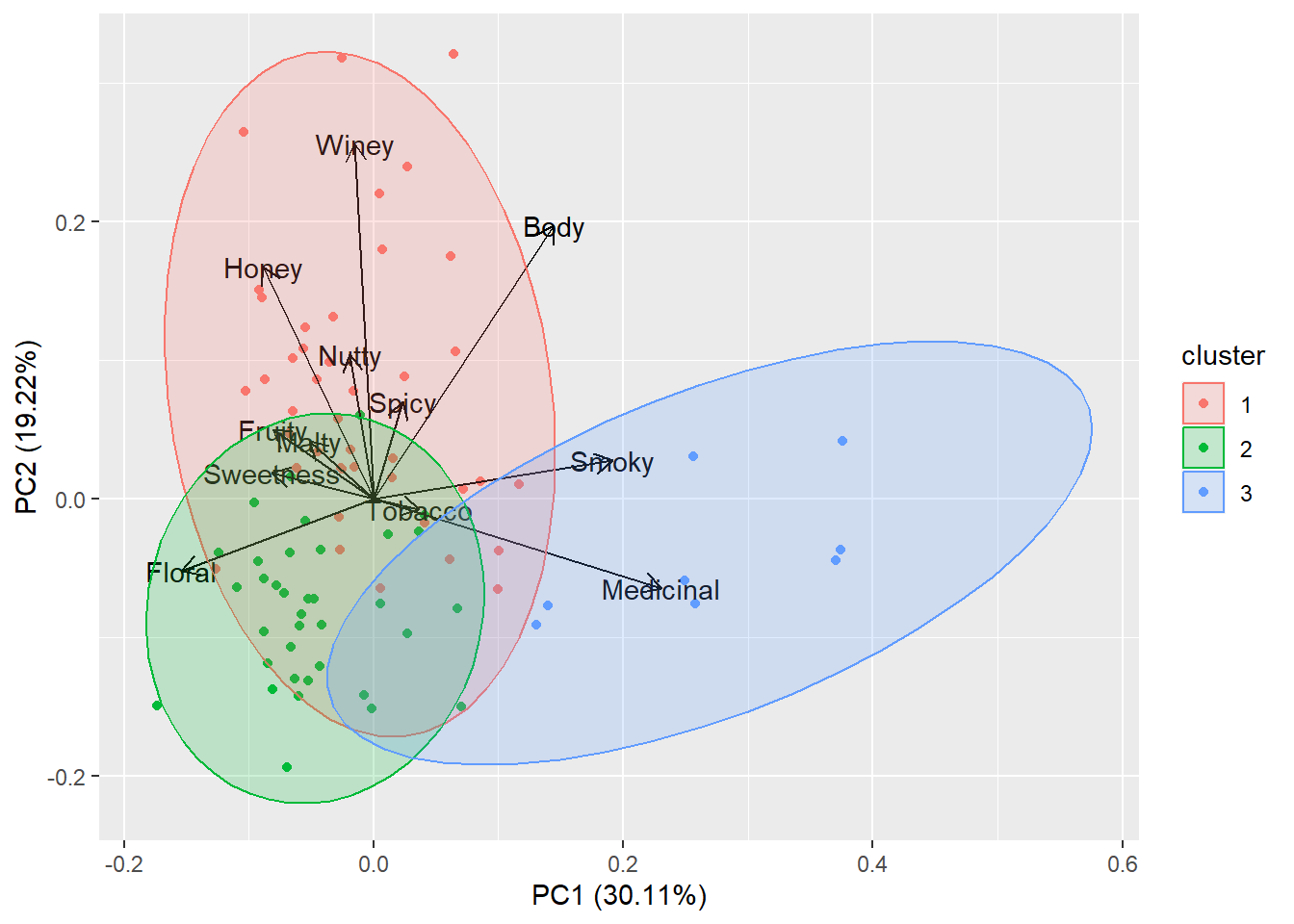
Die nächsten Abbildungen zeigen einmal das Ergebnis der Clusteranalyse mit zusätzlichem Biplot (PCA) sowie Clusteranalyse mit Markierungen zusammengesetzt aus den Namen der whiskey-Region und der Destllerie.
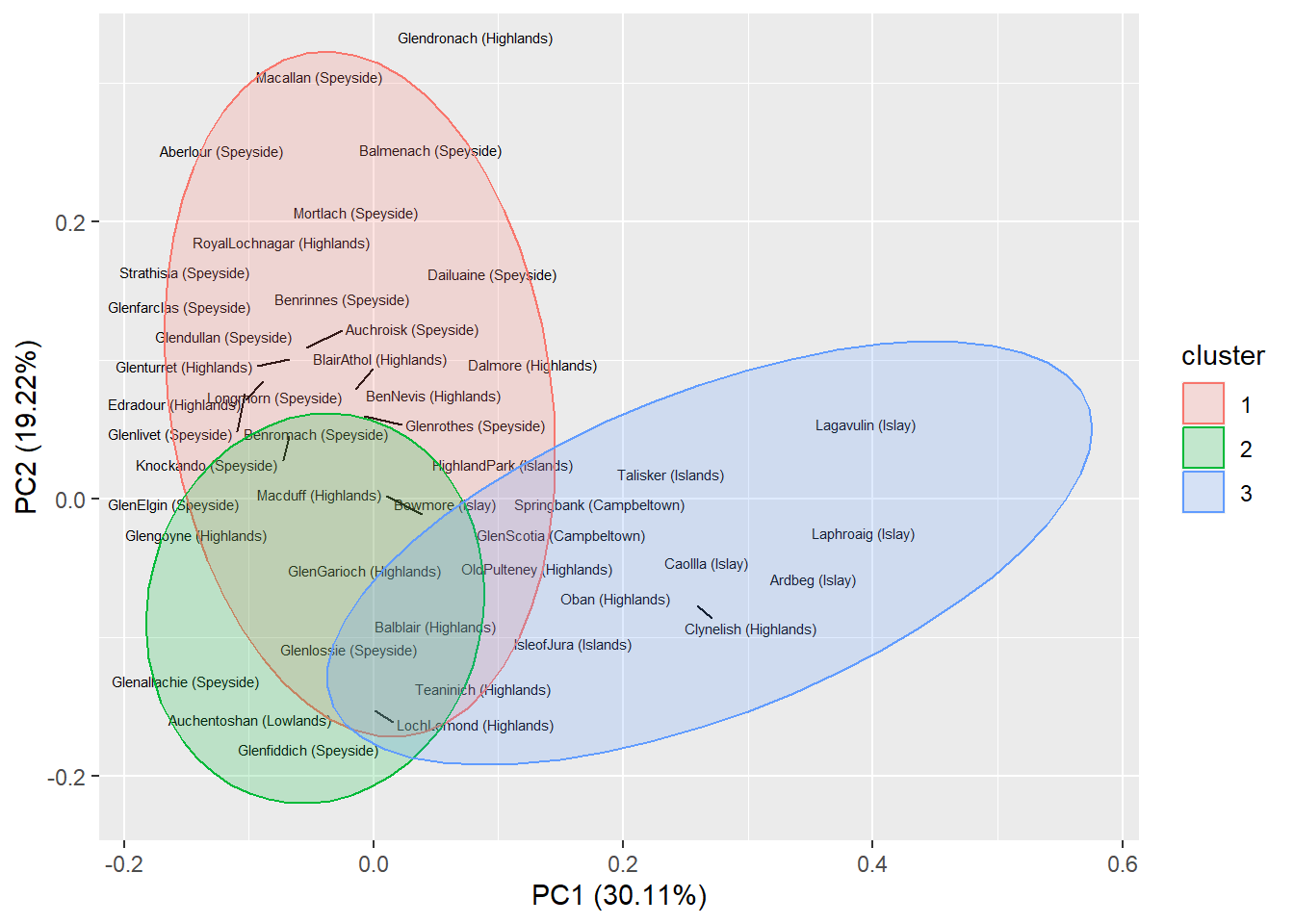
Die einfache Möglichkeit der Beschriftung von Punkten in einer zweidimensionalen Abbildung ( labelled PCA ) ist beeindruckend. Dabei wird versucht, das Überlappen von Markierungen zu vermeiden und die Labels voneinander und von den Datenpunkten automatisch zurückzudrängen (R package ggrepel). Wenn auch die Übersichtlickeit nicht besonders groß ist - die bei der Verwendung von Tablets eingebaute Zoomfunktion kann hilfreich sein.
Die eigentliche Analyse (Dimensionsreduktion, Visualisierung, Interpretation) soll auf der Basis des Biplots geschehen ( PCA ). Die autoplot Grafik zeigt eine Biplotdarstellung mit skalierten Hauptachsen (PC1 und PC2) einschließlich der erklärten Varianz der einzelnem Komponenten (30.11% bzw. 19.22%). Außerdem werden die Variablen als Biplot-Vektoren dargestellt. Deren Projektionen auf die Komponentenachsen (nicht eingezeichnet, durch den Nullpunkt) bestimmen die sog. Ladungen bezüglich der Hauptkomponenten. So wird PC1 haupsächlich über die Merkmale Medicinal und Smoky bestimmt, während die zweite Komponente von den Merkmalen Winey und Honey beeinflusst wird. Für Body gibt sich eine etwa gleich große Ladung für beide Komponenten.
Die Skalierung der beiden Hauptkomponentenachsen erlaubt keine direkte Interpretation. Häufig wird aber versucht, diesen Komponenten eine neue Bedeutung zu geben. So auch in diesem Beispiel:
Taken together, the principal components seem to reflect the following characteristics:
PC1 indicates the intensity of the taste: i.e. a smoky, medicinal taste (e.g. Laphroaig or Lagavulin) vs a smooth taste (e.g. Auchentoshan or Aberlour)
PC2 indicates the complexity of the taste: i.e. a well-balanced taste profile (e.g. Glenfiddich or Auchentoshan) vs a more characteristic taste profile (e.g. Glendronach or Macallan)
Diese Interpretationen beruhen auf den mittels autoplot erzeugten Grafiken. autoplot wird vor allem empfohlen, um Daten (z.B. genomische) schnell und bequem zu erkunden. Die Verwendung von zahlreichen default Parameterbesetzungen birgt aber auch Probleme. In den frühen Zeiten von R (zu Beginn des 21. Jahrhunderts) gab es umfangreiche Diskussionen, ob bei R-Funktionen Parameter überhaupt vorbesetzt sein sollten, oder ob es nicht besser wäre, denn Anwender dazu zu zwingen, sich über die Auswahl selbst Gedanken zu machen. Ergebnis der Diskussion - siehe autoplot.
Die nachfolgenden Abbildungen zeigen die Resulte für die Analyse der whiskey-Daten mittels pam-Clusteranalyse und der Visualisierung durch Hauptkomponentenanalyse mit zwei möglichst einfachen Kommandos, von deren Benutzung man sich eigentlich gleiche Resultate erwartet:
autoplot(pam(data, 3))clusplot(pam(data, 3))
Die Grafiken unterscheiden sich in zwei Punkten:
- Mit der Benutzung der
autoplotFunktion ist die Einbindung in das Systemggplot2verbunden, das elegant data visualisations kreiert (der Standardhintergrund - grau mit weißen Gitterlinien - erscheint eher für die Darstellung von Aktienkursen geeignet). - Die Ergebnisse der Visualisierung mittels Haupkomponentenanlyse sind unterschiedlich. So ist z.B. die durch die beiden Hauptkomponenten erklärte Varianz in der ersten Abblidung 30.11% + 19.22% = 49.33 %, in der zweiten Abbildung 42.91%.
Während der erste Punkt vernachlässigbar ist (und natürlich auch mit ggplot2 erzeugte Grafiken dem persönlichem Geschmack angepasst werden können), ist der zweite Aspekt kritischer zu bewerten. Zunächst ist es nicht einfach, den Grund für die unterschiedlichen Ergebnisse zu finden. Es zeigt sich, dass bei Verwendung der autoplot Funktion für pam die PCA mit den die Rohdaten durchgeführt wird, während bei der direkten Anwendung von pam die Hauptkomponentenanalyse mit normalisierten Variablen durchgeführt wird; d.h. die Variablen (Spalten der Datenmatrix) werden alle auf den Mittelwert 0 und die Standardabweichung 1 transformiert und damit vergleichbar gemacht. Insbesondere bei kontinuierlichen Messwerten auf unterschiedlichen Skalen (z.B. ) führt das zu sehr unterschiedlichen Ergebnissen.
Im folgenden soll daher kurz auf die verschiedenen Varianten der PCA sowie der unterschiedlichen Biplotdarstellungen eingegangen werden.
3 Analyse der Daten mit PCA Programmen
3.1 Allgemeines zur PCA
Das ursprüngliche Konzept der PCA (Jolliffe) bestand darin, die Dimension eines Datensatzes- bestehend aus einer großen Anzahl von korrelierten Variablen - zu reduzieren, wobei möglichst viel der ein den Daten vorhandenen Varianz erhalten werden sollte. Dies wird erreicht durch die Konstruktion von neuen Variablen (Hauptkomponenten - PCs), die unkorreliert sind und schrittweise von 1.Komponente an möglichts viel der Varianz, die in allen Variablen enthalten ist, beibehalten.
Ein neuerer Ansatz (Gower et. al) sieht es als das fundamentales Problem der PCA an, einr n-dimensionalen Datenmatrix (Matrix mit n Spalten entsprechend n Variablen) durch eine Matrix niederer Dimension (meist p = 2) bestmöglich zu approximieren.
3.1.1 Prescaling
Bevor aber über eine Approximation nachgedacht werden kann, muss über die Vergleichbarkeit der Variablen überprüft werden; die Verwendung von z.B Körpergröße in Meter und Gewicht in kg wird bei der PCA zu Schwierigkeiten führen. Eine Möglichkeit dieses Problem zu beheben, besteht darin, die Merkmale zu normalisieren. Auch andere Methoden der Skalierung (z.B. Logarithmieren bei positiven Variablen) können notwendig sein. Erst nach dieser Vorberietung kann der zweite Schritt betrachtet werden.
Allgemein wird davon ausgegangen, dass die PCA nicht geeignet ist für die Analyse kategorieller Daten. Für derartige Daten wurden Programme entwickelt (z.B. princal), die mittels optimal scaling die einzelnen Kategorien in numerische Werte umwandeln. In der Praxis wird jedoch dennoch häufig ein PCA angewandt (siehe princal von Mathias Döring).
3.1.2 Approximation
In einem zweiten Schritt wird für die vorbehandeten (pre-scaled) Daten eine optimale Approximation gesucht. Die Lösung dieses Problems leistet die sog. singular value decomposition (SVD). Diese decomposition ist jedoch nicht eindeutig; zwei Varianten stehen meist zu Verfügung:
Optimierung der Approximation der Abstände zwischen den Objekten (Reihen der Matrix)
Optimierung der Approximation der Korrelationen zischen den Variablen (Spalten der Matrix)
3.1.3 Biplotdarstellung
Die ursprüngliche Biplotdarstellung zur PCA orientiert sich am ersten Konzept (Hauptkomponenten). Biplots bilden die beiden ersten Hauptkomponenten als x bzw. y-Achse ab; diese Hauptkomponentenachsen sind skaliert, die Werte nicht interpretierbar. Variable sind als Vektoren dargestellt.
Beim zweiten Konzept (kalibrierte Biplots) bilden die Hauptkomponenten nur ein Skelett für die Abbildung. Bei dieser Darstellung wedenaus den Biplot-Vektoren kalibrierte Achsen. Durch orthogonale Projektion der Biplot-Punkte auf diese Achsen können die Variablenwerte in der ursprünglichen Dimension (z.B. Körpergewicht oder Körpergröße) abgelesen werden - allerdings die approximierten Werte.
3.2 Analyse der whiskey Daten
Bei den whiskey Daten handelt es sich um Rating-Daten (kategorielle Daten auf Nominalskalenniveau, Bewertung von 86 Malt-Whiskies bezüglich 12 verschiedener Geschmackskategorien auf einer Skala von 0 bis 4). Zur Analyse derartiger Daten stehen verschiedene statistische Verfahren und Auswertungssoftware zur Verfügung (z.B. categorical principal component analysis, function princals im R package Gifi). Hier ist insbesondere auch die Verwendung nominal-skalierter Variabler vorgesehen.
Klassische PCA-Analysen erfordern Daten auf Skalenebene (Intervall oder Verhältnis). Oft wird jedoch davon ausgegangen, dass auch Rating-Daten auf Skalenebene vorliegen. Ob diese Entscheidung gerechtfertigt ist, hängt von der jeweiligen Situation ab (eher zutreffend, wenn die Anzahl der geordneten Kategorien groß ist). Bei der Interpretation der Ergebnisse sind aber immer die Besonderheiten zu berücksichtigen (z.B. gleicher Abstand zwischen den Kategorien).
Die Anwendung einer klassischen PCA zur Analyse der vorliegenden Daten ist nicht ohne Probleme. Falls die Annahme der geichen Abstände zwischen den Kategorien gerechtfertigt scheint, ist noch zu klären, ob die Daten normalisiert werden sollen oder nicht. Bei der Bewertung der Kategorie Tobacco treten beispielsweise nur die Ausprägungen 0 und 1 auf. Bei Verwendung von normalisierten Daten wird der Wert der Kategorie 1 auf 3.1 angehoben.
Die Analyse im DATA SCIENCE BLOG basiert auf nichtnormalisierten Daten und der Verwendung einer distanzoptimierenden PCA. In der folgenden Abbildung wird die Information über die Zugehörigkeit der 86 Destillerien zu den schottischen whiskey-Regionen zur Beschreibung mit dargestellt (geht nicht in die Berechnung ein: PCA ist eine Methode des unuspervised learnings).
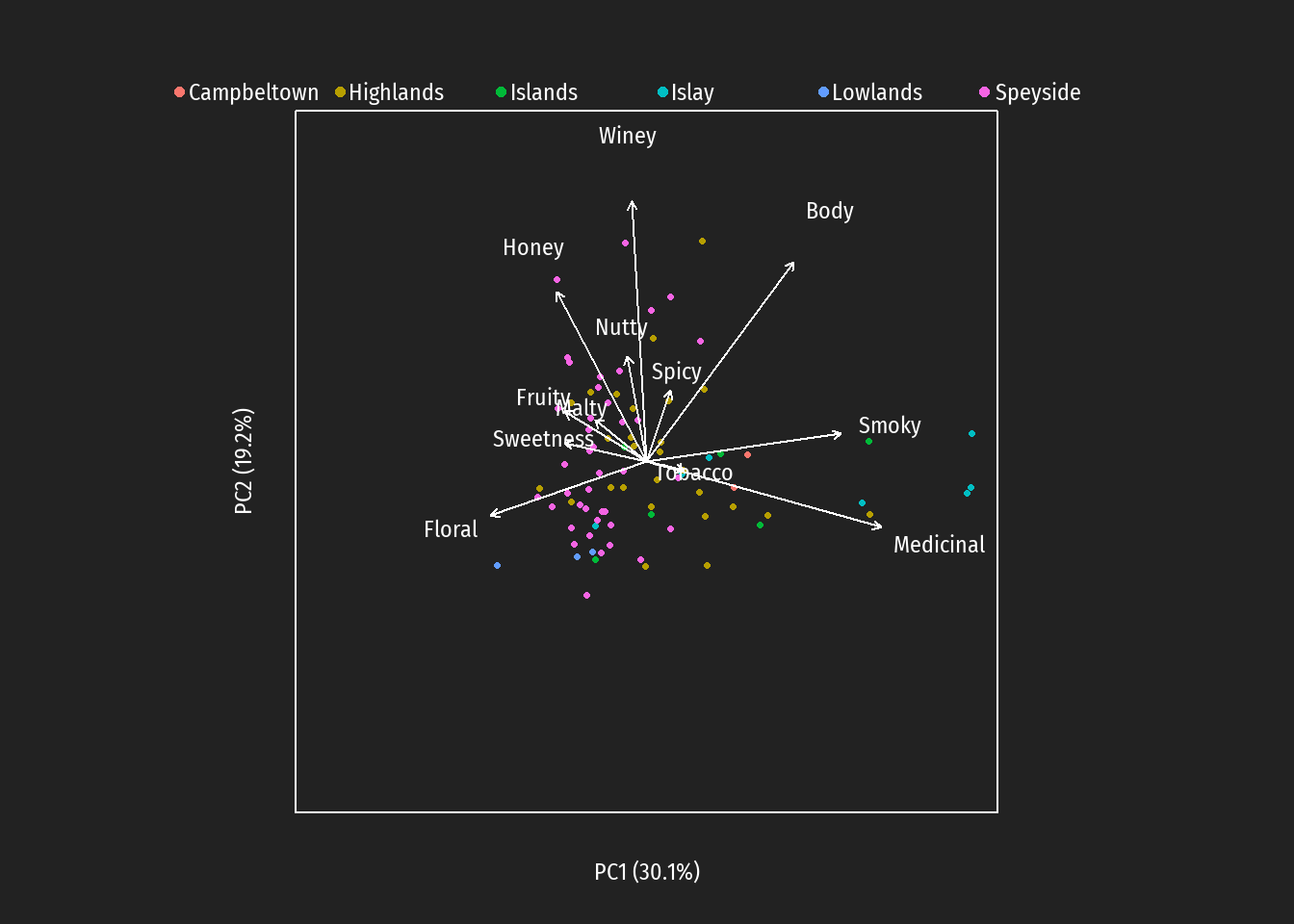
Die Abbildung lässt eine gewisse Clusterung der Regionen bezüglich der Variablen erkennen. Beispielsweise haben etliche Islay Destillerien hohe Skalen-Werte bei den Geschmacksskatetegorien Medicinal und Smoky. Außerdem sind Abhängigkeiten zwischen den Variablen abzulesen (Biplot-Vektoren in ähnlicher Richtung; z.B. hohe Abhängigkeit zwischen Medicinal und Smoky). Gemäß dem Hauptkomponentenkonzept sind die erklärten Varianzen für Komponente 1 (PC1) und Komponente 2 (PC2) angegeben. Die Achsen selbst und die Skalierung sind weggelassen. In vielen empirischen Untersuchungen hat sich eine inhaltliche Interpretation der Hauptkomponenten als schwierig und oft inhaltlich ziemlich willkürlich erwiesen. Deswegen werden auch kalibrierte Biplots zur Visualisierung der PCA-Ergebnisse benutzt.
Die folgenden Abbildungen zeigen den Übergang vom klassischem zum kalibrierten Biplot.
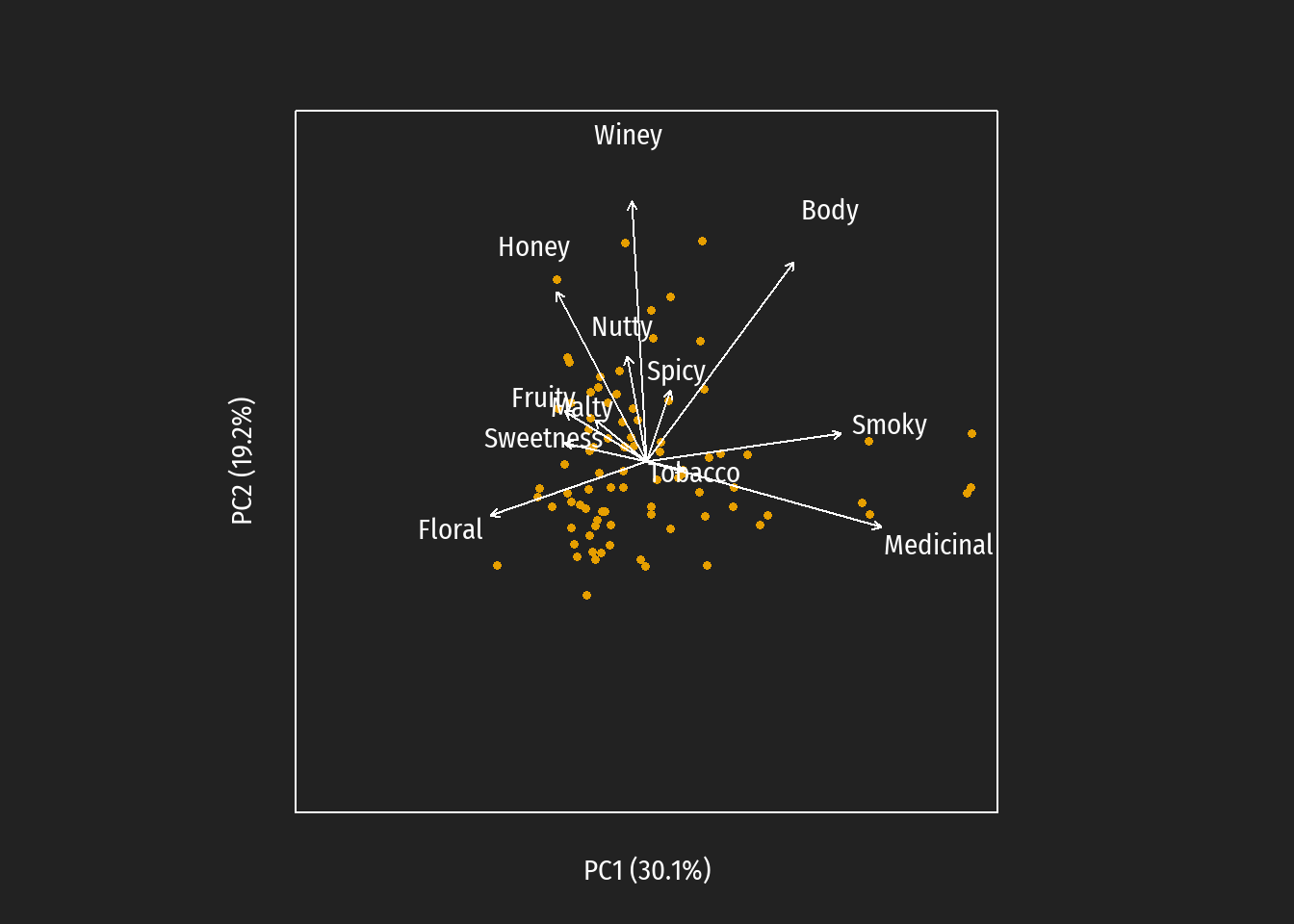
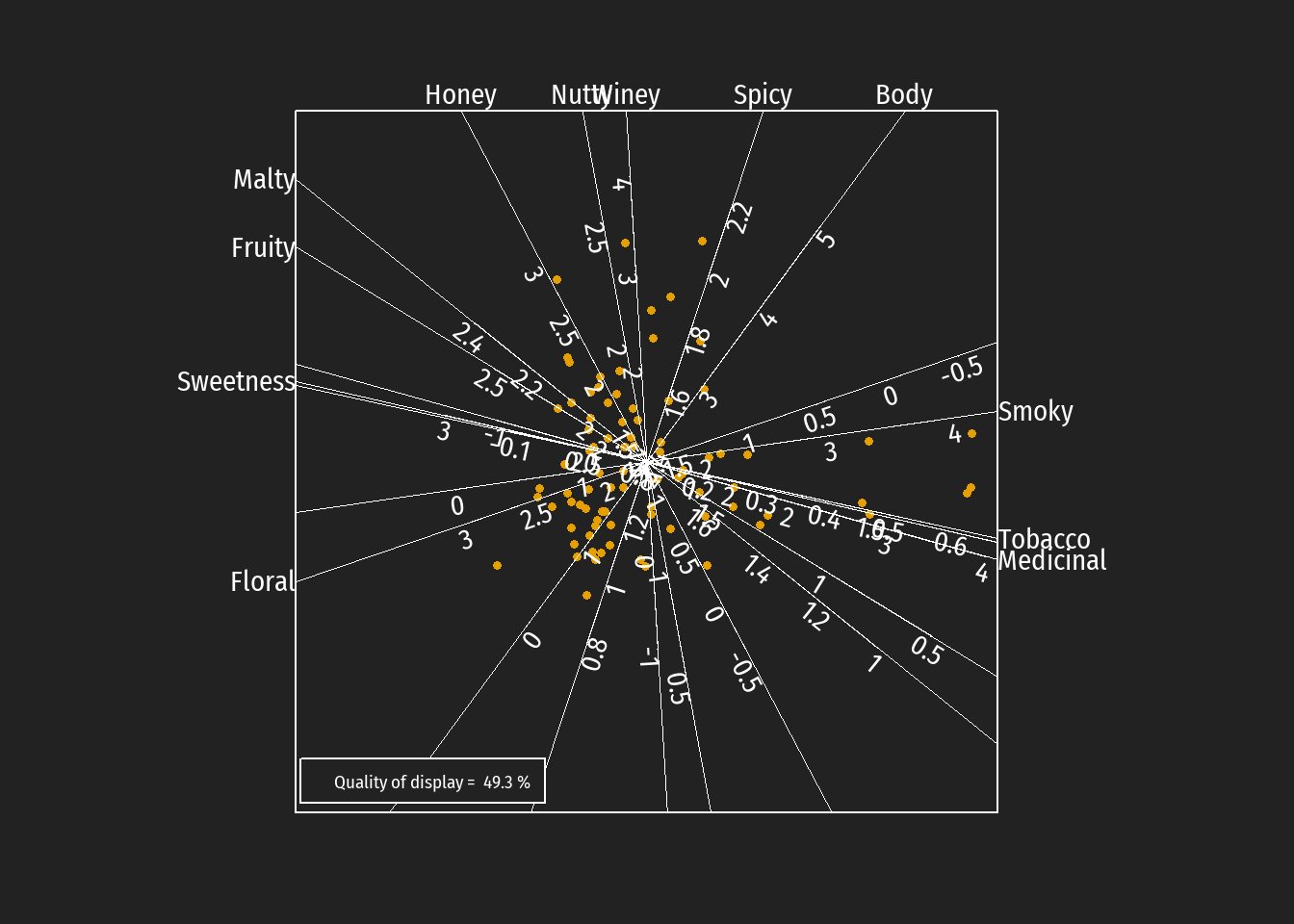
Im kalbrierten Biplot sind die Vektoren ersetzt durch Achsen mit entsprechender Kalibrierung. Diese erfolgt in der Einheit der ursprünglichen Merkmale (im Beispiel: Skalenwerte zwischen 0 und 4). Dargestellt sind jedoch die approximierten Werte, weswegen auch negative bzw. Werte über 4 auftreten können. Anstelle der erklärten Varianz der Hauptkomponenten wird unter dem Begriff Quality of display die Summe der erklärten Varianzen beider Hauptkomponenten angegeben.
Darüberhinaus können in einer Tabelle die sog. predictivity Werte zusammengefasst werden. Diese Maßzahlen spiegeln die Korrelation zwischen den Original- und den approximierten-Werten (in zwei Dimensionen) für jeder einzelne Variable wider. Sie stehen in eine gewissen Beziehung zu der Länge der Biplot-vektoren im klassischen Biplot.
| Body | Sweetness | Smoky | Medicinal | Tobacco | Honey | Spicy | Winey | Nutty | Malty | Fruity | Floral | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| predictivity | 0.78 | 0.2 | 0.73 | 0.84 | 0.2 | 0.52 | 0.09 | 0.71 | 0.16 | 0.14 | 0.2 | 0.51 |
Ein häufiges benutztes Argument gegen die Verwendung von kalibrierten Biplots ist die Unübersichtlichkeit bei einer größeren Variablenzahl (bei einer wirklich größeren Zahl sind allerdings auch klasssische Biplots unübersichtlich). Eine Möglichkeit dies zu umgehen besteht darin, nur einige wenige skalierte Achsen darzustellen. Die Auswahl dieser Achsen kann auch auf Grund von inhaltlichen Überlegungen geschehen; auf keinen Fall sollten aber Merkmale mit geringer predictivity abgebildet. Für die Beispielsdaten wurden vier Merkmale mit der höchsten predictivities ausgewählt (Medicinal wegen der hohen Korrelation zu Smoky weggelassen).
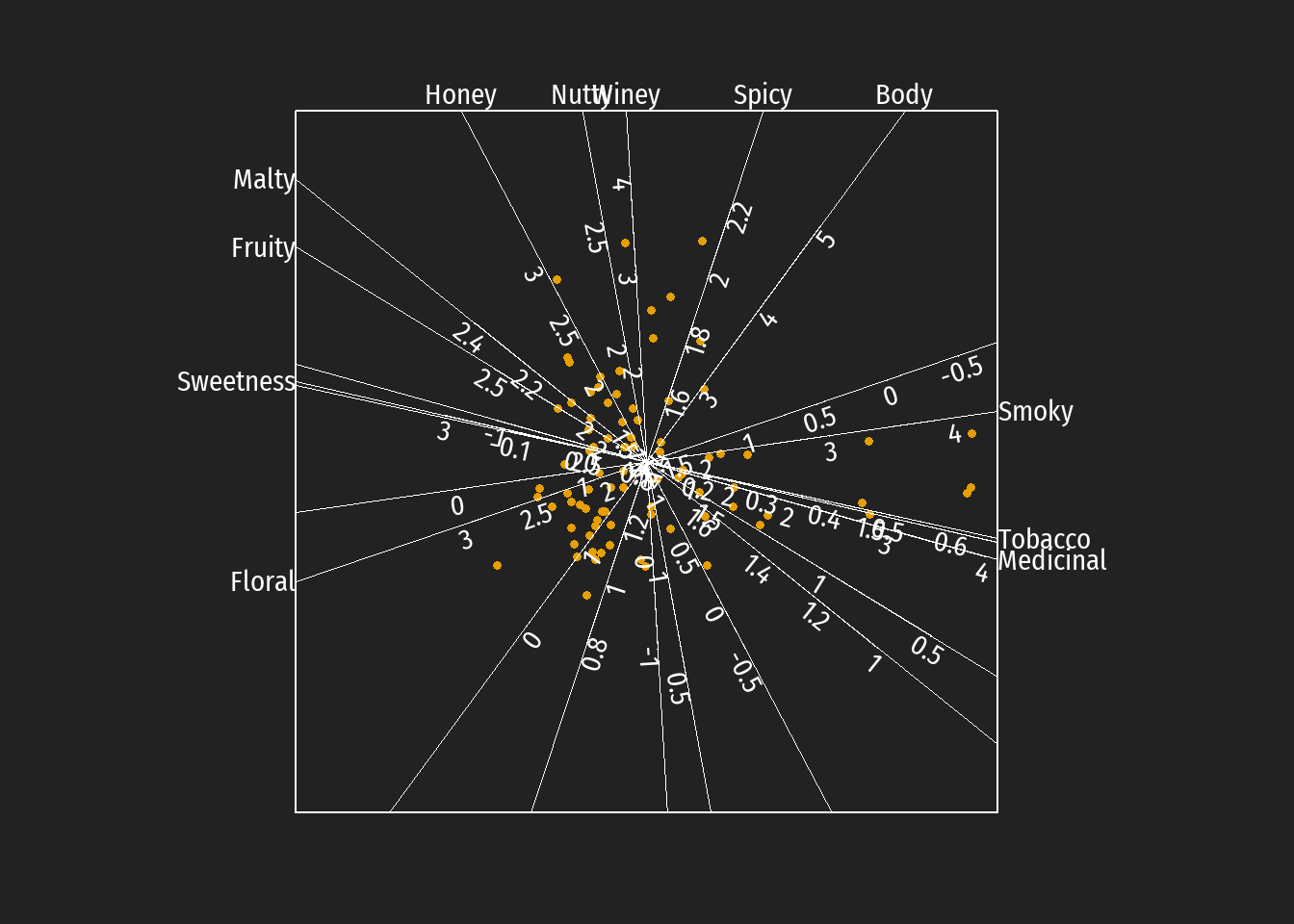
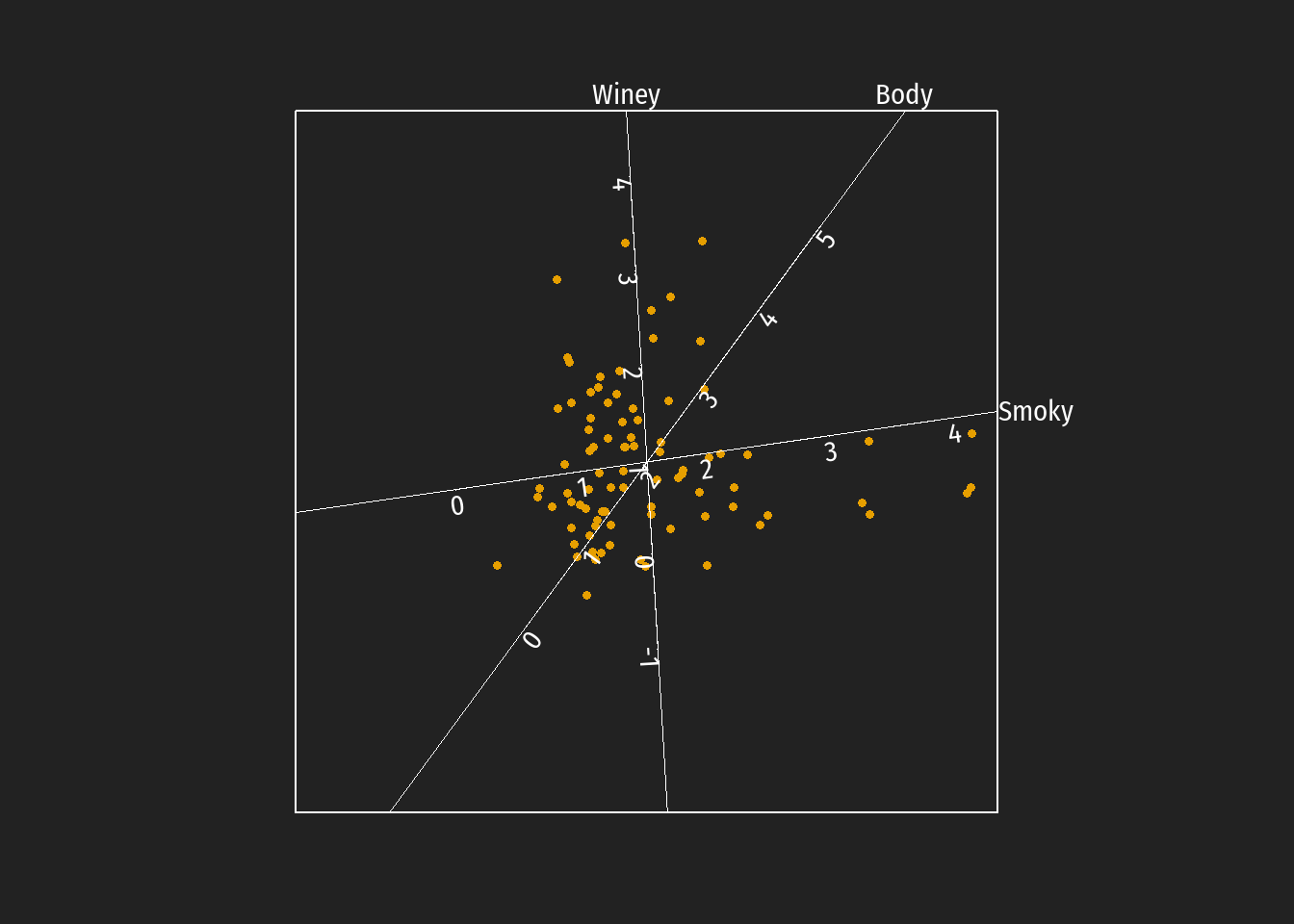
Diese kalibrierte Biplotdarstellung ist nicht eindeutig. Die Abbldungen können einer beliebigen Rotation sowie beliebigen orthogonalen Verschiebungen der Achsen unterzogen werde. Die approximatierten Werte der Markmale - als Projektionen auf die jeweiligen Achsen - bleiben dabei erhalten. Zur Beschreibung von bevorzugt auftretende Geschmackstendenzen bei Destillerien unterschiedlicher schottischer whiskey Regionen können in diesem Biplot die unterschiedlichen Regionen auch farbig markiert werden.
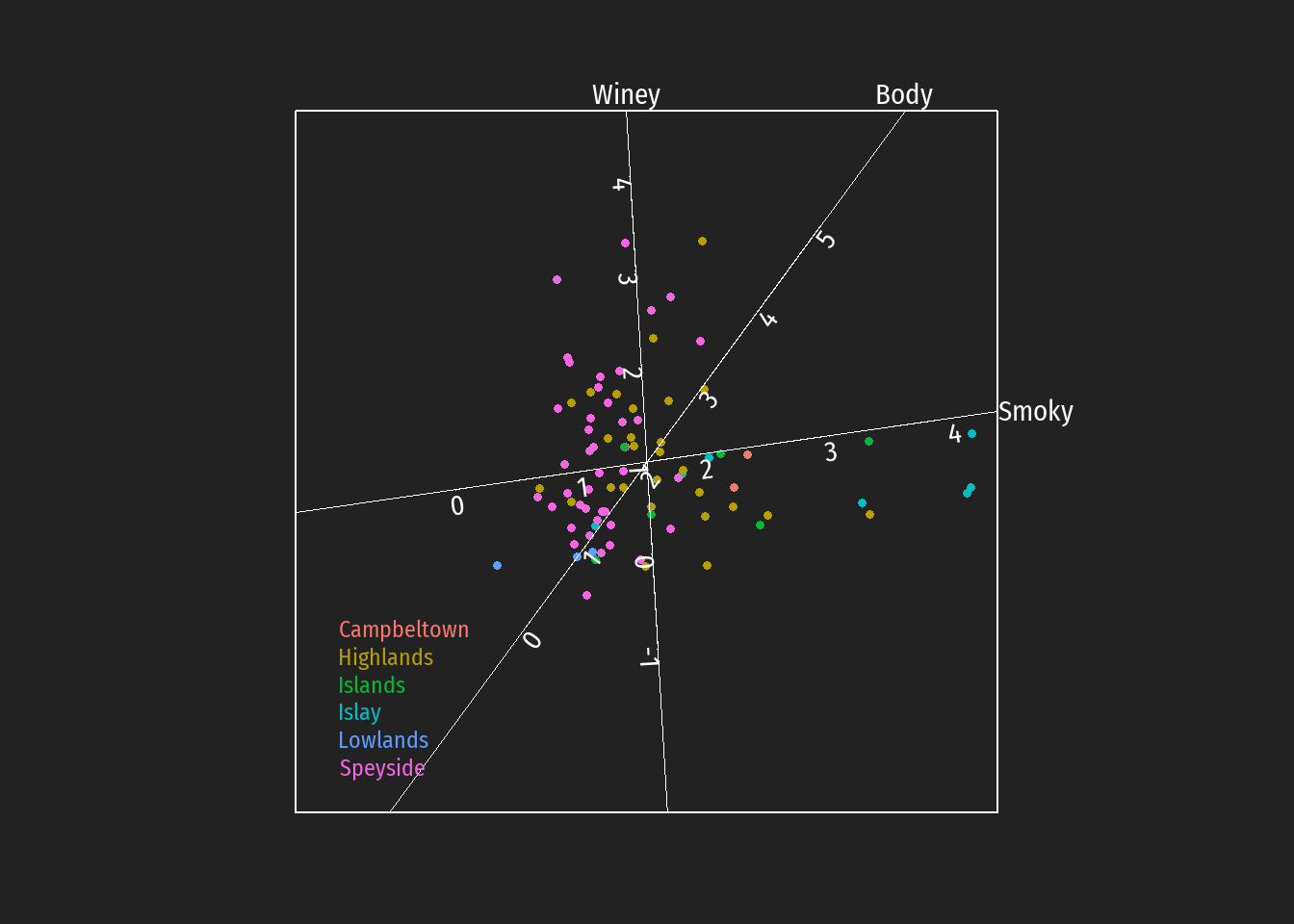
Durch Einzeichnen der Projektionen auf die Achsen können z.B. Hypothesen bezüglich bevorzugt auftretende Geschmackstendenzen bei Destillerien unterschiedlicher schottischer whiskey Regionen leichter überprüft werden (in den folgenden Abbildungen dargestellt für die Regionen Islay, Islands, Lowlands und Campbeltown).
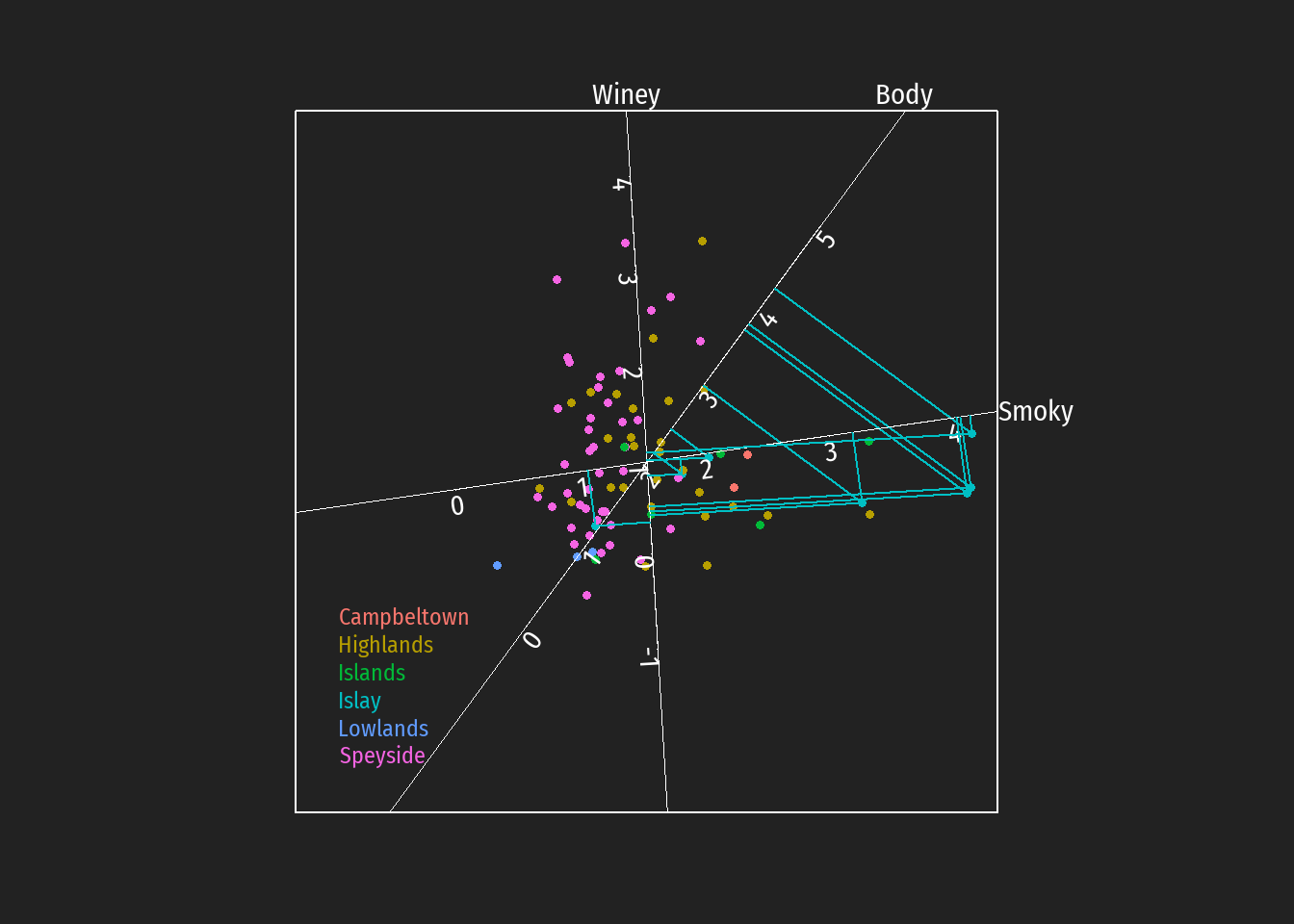
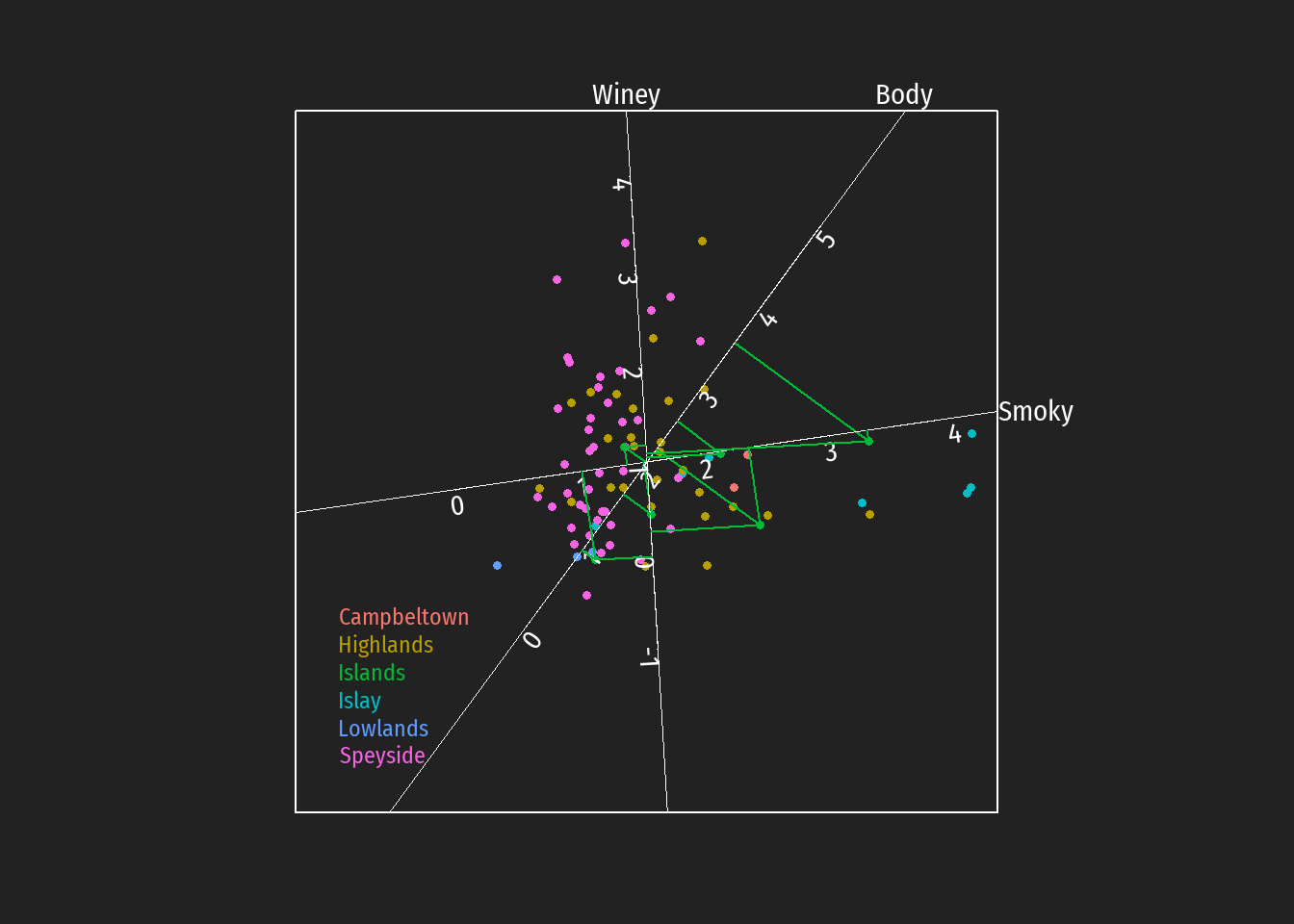
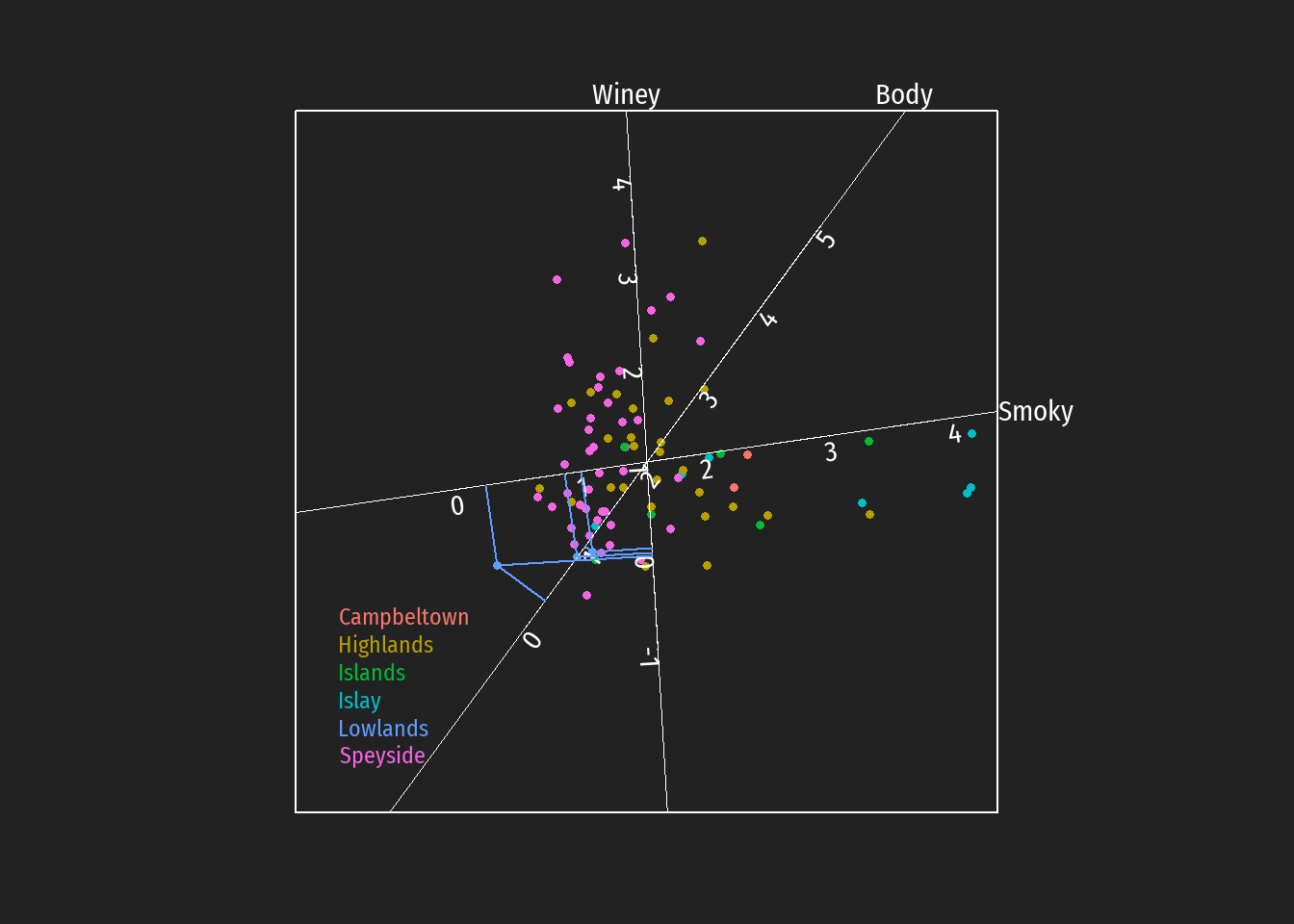
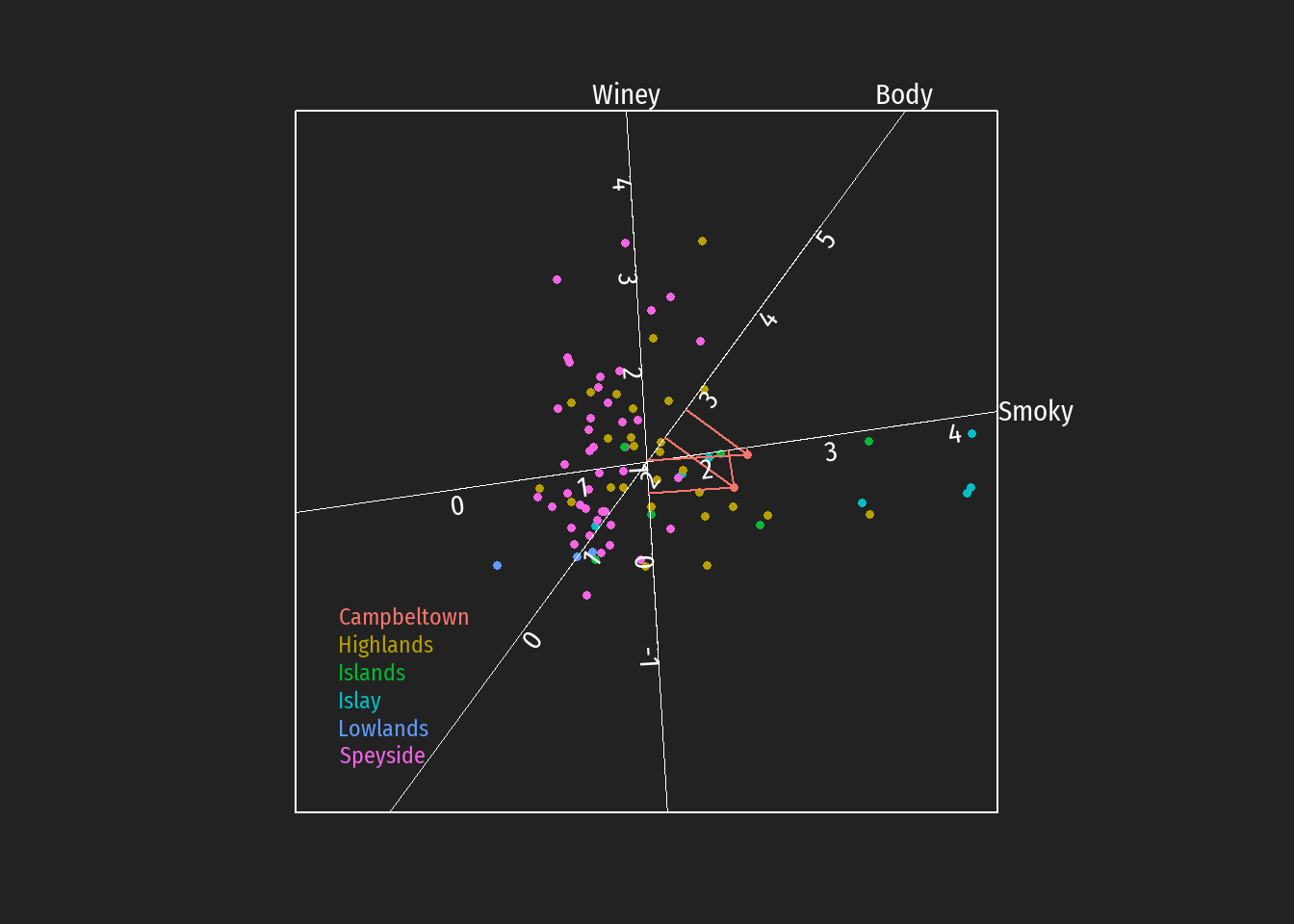
Es zeigt sich:
Islands, and Islay regions are known for its peaty and smoky flavours.
Light and delicate whiskies have a more prominent floral note, which is common in whiskies produced in the Lowlands region (Das nicht dargestellte Merkmal Floral ist hoch negativ korreliert mit Smoky; niederes Rating bezgl. Smoky impliziert hohes Rating bezgl. Floral .
Die beiden whiskeys der Campbeltown Destillerien ( GlenScotia und Springbank) nehmen bezüglich aller dargestellten Geschmackskategorien mittlere Positionen ein ( well-ballanced).
Weitere Interpretationen von Matthias Döring aus dem DATA SCIENCE BLOG:
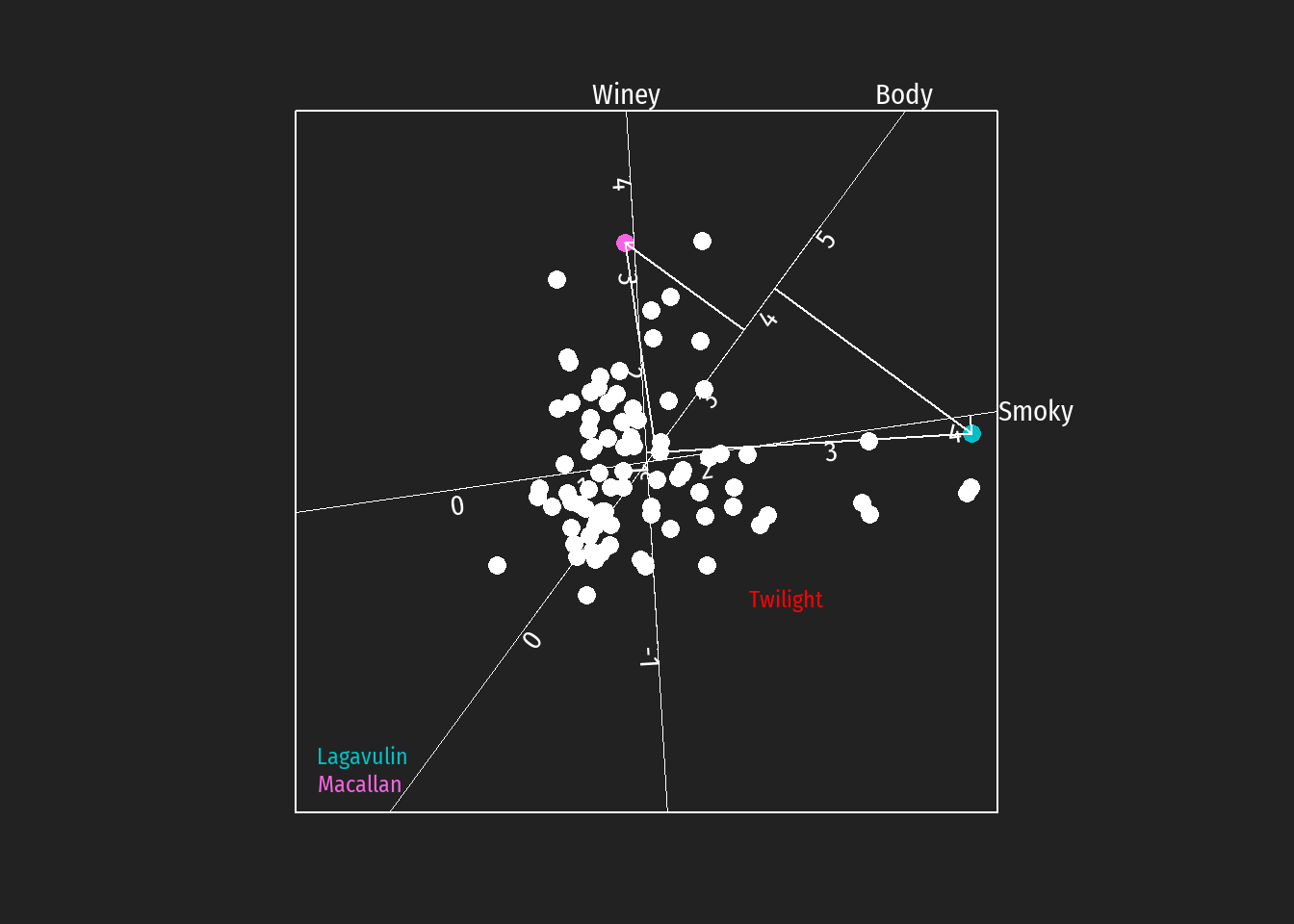
I find it interesting that the two-dimensional projection of whiskeys contains large open areas. This could indicate one of two things: There is still a lot of potential for experimenting with new, exciting types of whiskeys. There are just so many combinations of taste that are possible and go well together.
I am inclined to go with the second option. Why? In the PCA plot, the lower right is the largest region in which no samples reside. Looking at the whiskeys that come close to this region, we find that those are Macallan on the y-axis and Lagavulin on the x-axis. Macallan is known for its complex taste and Lagavulin is known for its smoky taste.
A whiskey that comes to lie on the lower right of the 2-dimensional PCA space would have both properties: it would be complex and smoky at the same time. I guess that a whiskey exhibiting both characteristics would be just too much for the palate to handle (i.e. smokiness masks complexity).
This unexplored region of taste can be considered to be the whiskey twilight zone. Regarding the twilight zone there are two questions. First, would it be possible to produce whiskeys to fill that void and, second, and probably more important, how would these whiskeys taste?
Zur Veranschaulichung nochmals die kalibrierte Biplotdarstellung (Twilight, Lagavulin und Macallan markiert).
References
Wylie, Christopher. 2016. MINDF*CK. Dumont Buchverlag. https://www.dumont-buchverlag.de/buch/wylie-mindf-ck-9783832181345/.